| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java Performance:
Profiling Strategien - Performance HotSpots
Wie findet man funktionale Performance
HotSpots?
JavaSPEKTRUM, Januar 2006
|
Dies ist das Manuskript eines Artikels, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im JavaSPEKTRUM erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Im vorangegangenen Beitrag dieser Kolumne haben wir uns mit dem Profiling von Java-Anwendungen und insbesondere mit Profiler-Werkzeugen beschäftigt. Beim Profiling geht es um Messungen, die u.a. Aussagen über die Performance einer gesamten Anwendung liefern. Solche Messungen werden während der Entwicklung vorgenommen, um Schwachstellen im Programm, wie zum Beispiel Performance-HotSpots und –Bottlenecks, zu identifizieren und durch ein anschließendes Tuning zu beseitigen. Für das Profiling verwendet man in der Regel entsprechende Profiler-Tools. Im letzten Beitrag haben wir uns angesehen, wie solche Profiler prinzipiell funktionieren und welche Art von Analysen man damit machen kann. In diesem und dem nächsten Beitrag diskutieren wir, wie man diese Tools verwendet, um verschiedene Profilings zu machen. Diesmal geht es um das Aufspüren von Performance HotSpots. Das nächste Mal diskutieren wir Memory HotSpots und Memory Leaks.
Ein Profiling kann ganz unterschiedliche Aspekte eines Programms untersuchen. Wir interessieren uns in erster Linie für die Identifikation von Schwachstellen, die die Performance der Anwendung negativ beeinflussen. Der offensichtlichste Ansatzpunkt für ein Performance-Tuning sind Methoden, die viel Zeit verbrauchen und oft aufgerufen werden - die sogenannten „Performance HotSpots“ (später in diesem Beitrag auch als „Functional HotSpots bezeichnet, weil es auch noch andere Arten von HotSpots gibt, die sich auf die Performance auswirken). Wenn man die Performance eines solchen HotSpots verbessern kann, wirkt sich die Verbesserung spürbar auf die Performance der gesamten Anwendung aus. Man wird deshalb im Rahmen eines Profilings nach solchen Performance HotSpots suchen.
Ein Profiling kann aber noch ganz andere Schwachstellen im Programm
aufdecken. Beispielsweise ist exzessiver Speicherverbrauch ebenfalls
ein Schwachpunkt, der sich indirekt über höheren Aufwand für
die Garbage Collection negativ auf die Performance auswirkt. Im Rahmen
eines Profilings kann auch die Thread-Synchronisation (z.B. das Warten
auf Locks und Signale) daraufhin überprüft werden, ob es so funktioniert,
wie
es im Design beabsichtigt wurde, oder ob sich Fehler (z.B: zuviel oder
zu wenig Synchronisation) eingeschlichen haben.
Überblick über die verschiedenen Profiling-Tätigkeiten
Verschaffen wir uns also erst einmal einen Überblick über die Aktivitäten, die Profiler-Tools für Java typischerweise unterstützen, ehe wir uns die einzelnen Aktivitäten im Detail ansehen.- Functional-HotSpots. Performance-Profiling wird hauptsächlich gemacht, um funktionale Performance-Engpässe zu identifizieren, also Methoden, die sehr viel Zeit verbrauchen, weil sie entweder sehr oft aufgerufen werden, oder weil sie sehr lange brauchen für jeden einzelnen Ablauf. Solche Methoden werden anschließend im Rahmen eines Performance-Tunings entsprechend überarbeitet und in Hinsicht auf ihre Performance optimiert.
- Memory-Allocation-HotSpots. Hierbei versucht man sich einen Überblick über den Speicherverbrauch der Anwendung zu verschaffen, mit dem Ziel, den Memory Footprint des Programms insgesamt zu minimieren. Dabei sucht man nach Object-Creation-HotSpots, also Stellen im Programm, wo auffallend hoher Speicherverbrauch festzustellen ist. Möglicherweise werden dort Objekte unnötig erzeugt und man kann diese Speicherverschwendung beseitigen. Wenn die Objekte tatsächlich gebraucht werden, dann kann man immer noch überlegen, ob sich der Speicherverbrauch durch Wiederverwendung von bereits allozierten Objekten reduzieren lässt.
- Memory-Leaks. Zum Memory-Profiling gehört auch die Suche nach Memory Leaks, also nach Speicher, der logisch gar nicht mehr gebraucht wird, aber immer noch über eine unerwünschte Referenz erreichbar ist und damit vom Garbage Collector nicht aufgeräumt werden kann. Das ist eigentlich ein Programmierfehler und kann mittels eines Memory.-Profilings gefunden werden.
- Thread-Aktivität. Mit Hilfe eines Profilers kann man prüfen, ob die Threads der Anwendung die CPU so nutzen, wie es geplant war. Beispiel: bei einem Thread, der hauptsächlich rechnet und verarbeitet, würde man eine hohe CPU-Nutzung erwarten; bei einem Thread, der an einem Socket hängt und auf Requests wartet, wird man eher eine geringe CPU-Nutzung erwarten. Wenn der CPU-Verbrauch der Threads nicht den Erwartungen entspricht, dann hat man entweder die falschen Erwartungen was die Tätigkeiten der Threads angeht oder die Implementierung ist tatsächlich fehlerhaft und muss korrigiert werden.
- Thread-Contention. Dabei geht es um die Verfolgung der Thread-Zustände und insbesondere um die Identifikation und Vermeidung von Starvation und Deadlocks. Es wird verfolgt, welche Threads welche Monitore halten und freigeben, und kann daran erkennen, ob sich Threads unnötig behindern oder blockieren. Auf diese Weise können Fehler in der Synchronisierung, wie zum Beispiel Deadlocks, festgestellt werden. Man kann mit dem Thread-Profiling auch überprüfen, ob alle Threads wie geplant und erwartet ausgelastet sind, oder ob einzelne Thread unerwünscht viel Zeit mit dem Warten auf irgendwelche Locks verbringen. Diese unerwünschten Wartezustände kann man dann versuchen zu beseitigen.
- Code Coverage. Das ist eigentlich eher ein Nebenprodukt des Profilings. Hier wird der Testüberdeckungsgrad gemessen und man kann daran die Güte und Vollständigkeit einer Testsuite messen. Dabei stellt man u.U. fest, dass das Programm toten Code enthält, den man vielleicht besser eliminieren sollte. Oder aber man stellt fest, daß die Tests nicht ausreichend sind und vervollständigt seine Testsuite.
Für die Demonstration haben wir einige kostenlose und ein kommerzielles
Tool ausgewählt, nämlich den HPROF zusammen mit HPjmeter und
einem Eclipse Profiler PlugIn namens EclipseColorer (alles Freeware) und
Borland’s OptimizeIt (kommerzielles Produkt). Leider funktionieren
derzeit noch nicht alle Tools mit Java 5.0. Beispielsweise gibt es
keinen EclipseColorer für die Eclipse-Version 3.1; das ist die Version
von Eclipse, die Java 5.0 unterstützt. HPROF, HPjmeter und OptimizeIt
stehen für Java 5.0 aber bereits zur Verfügung. Die Versionsabhängigkeiten
sind lästig, aber auf die generelle Vorgehensweise beim Profiling
habe sie keinen Einfluß.
Vorbereitungen für ein Profiling
Ehe man sich bestimmten Profiling-Tätigkeiten widmen kann, ist eine Reihe von Vorbereitungen nötig.Repräsentativer Programmablauf
Unerlässlich für ein aussagekräftiges Ergebnis, ganz egal welche Art von Information beim Profiling eingeholt werden soll, ist ein repräsentativer Programmablauf. Für die Messung sollte die Anwendung hinreichend lange in einer typischen Konstellation laufen, d.h. mit einer Anzahl von repräsentativen Use-Cases und einer für den Normalbetrieb typischen Belastung. Dafür kann es erforderlich sein, daß ein entsprechender Testrahmen mit Simulatoren, z.B. für Streßerzeugung durch eine große Anzahl von Clients, implementiert werden muss.Starten des Profiler-Tools
Dann muss das Programm im oder mit dem Profiler gestartet werden. Das funktioniert je nach Tool unterschiedlich, wie wir schon im vorangegangenen Artikel angedeutet haben. Hier einige Beispiele zur Illustration.HPROF/HPjmeter
Die Anwendung, die wir den Profiling unterziehen wollen, wird ganz normal in einer Sun JVM gestartet, wobei der Profiler in Java 1.4 über die JVM-Option -Xrunhprof[:options] und in Java 5.0 über die JVM-Option -agentlib:hprof[=options] angestoßen und gesteuert wird. HPROF macht Ausgaben auf eine Datei (oder auf einen Socket) in ASCII (oder Binärformat). Den Output kann man anschließend mit einem Tool wie HPjmeter auswerten und anzeigen lassen, indem man dem HPjmeter die Ausgabedatei von HPROF als Eingabedatei gibt. Es werden also erst Daten gesammelt, danach wird ausgewertet. HPROF ist also ein typischer Post-Mortem-Profiler, dessen Agent in einer separaten Bibliothek ausgeliefert wird. (Zur Architektur von Profiler-Tools siehe / KRE3 /.)EclipseColorer
Wir haben u.a. einen PlugIn für Eclipse verwendet, den EclipseColorer (siehe / ECOL /), mit dem man einen Profiler-Lauf aus dem Eclipse IDE heraus starten kann. Der PlugIn wertet die Ausgaben seines Profiler-Agenten simultan aus und zeigt entsprechende Auswertungen und deren Änderungen fortlaufend im Eclipse an. Das Profiler-Frontend kommuniziert hier interaktiv mit dem Profiler-Agenten.OptimizeIt
Kommerzielle Tools wie OptimizeIt integrieren den Start der Anwendung üblicherweise in das Tool. Hier wird die Anwendung über die Benutzeroberfläche des Tools gestartet. (Die kommerziellen Tools können auch in verschiedene IDEs wie z.B. Eclipse integriert werden.) Während die Anwendung läuft, können dann für eine gewisse Zeitspanne Meßdaten erhoben werden, indem man manuell Beginn und Ende der Messung per Knopfdruck bestimmt. Das Tool sammelt dann in dieser Zeitspanne Daten, deren Auswertung anschließend angeschaut werden kann. Auch kommerzielle Tools wie OptimizeIt können sich in der Regel in gebräuchliche IDEs wie Eclipse integrierenNach diesen Vorbereitungen können wir nun diverse Profilings durchführen. Sehen wir uns als erstes die Performance HotSpots an.
Funktionale Performance-HotSpots aufspüren
Hierbei geht es um die Suche nach Tuning-Potential. Es wird versucht, mit Hilfe eines Profilers diejenigen Methoden zu identifizieren, die oft aufgerufen werden und viel Zeit kosten. Diese sogenannten Performance-HotSpots sind ideale Kandidaten für ein Tuning, weil sich die Performance-Verbesserung in einer solchen Methode natürlich mehr lohnt, als bei einer Methode, die nur selten aufgerufen wird oder ohnehin schon verhältnismäßig schnell ist. Wie findet man nun die Tuning-Kandidaten?Profiling-Information
Alle Profiler-Tools bieten die Möglichkeit, die Methoden aufzulisten geordnet nach der Häufigkeit, mit der sie aufgerufen werden und geordnet nach der Zeit, die sie für den Ablauf benötigen. Wie diese Information dargestellt wird, ist von Tool zu Tool anders. Verschieden ist auch, welche Information angezeigt wird.- Inclusive vs.Exclusive. Bei der Ablaufzeit wird unterschieden nach dem Zeitverbrauch der Methode allein (engl. exclusive method time) und dem Zeitverbrauch der Methode insgesamt, d.h. inklusive aller Methoden, die von dieser obersten Methode aufgerufen werden (engl. inclusive method time). Eine Methode kann beispielsweise einen hohen inklusiven, aber einen geringen exklusiven Zeitverbrauch haben. Das passiert, wenn die Methode selber nichts weiter tut, als lediglich andere Methode aufzurufen, die den hohen Zeitverbrauch verursacht.
- CPU vs. Elapsed. Bei der Zeitangabe kann es sich um die Angabe der verbrauchten CPU-Zeit (engl. cpu time) oder aber um die tatsächlich abgelaufene Zeit (engl. elapsed oder clock time) handeln. Eine Methode, die sehr viel Zeit mit Warten (auf I/O, im Zusammenhang mit Thread-Synchronisation, etc.) verbringt, wird einen hohen Elapsed-Zeitwert haben, aber einen geringen CPU-Zeitwert.
- Milli vs. Micro. Die Maßeinheit für die Zeitangabe kann in Millisekunden oder Microsekunden sein. Normalerweise wird in Millisekunden gemessen. Die Messung in Microsekunden erfordert häufig mehr Zeit für die Messungen selbst, was stärker zu einer möglichen Verfälschung der Meßergebnisse beiträgt.
- Samples vs. Instrumentation. Es gibt zwei Arten, um Daten über die Ablaufzeiten der Methoden zu beschaffen: Stichproben (engl. samples) und Instrumentierung (engl. instrumentation). Weil die beiden Techniken zu unterschiedlichen Ergebnissen führen können und unterschiedlich bewertet werden müssen, sehen wir sie uns genauer an.
Stichproben vs. Instrumentierung
Um Stichproben zu nehmen, unterbricht der Profiler das laufende Programm in regelmäßigen Abständen und schaut sich den Stack aller Threads an, um festzustellen, welche Methoden gerade aktiv sind. Bei dieser Art des Profilings erhält man keine exakten Daten. Methoden mit sehr kurzen Ablaufzeiten werden nicht korrekt erfaßt, weil sie teilweise zwischen den Sampling-Zeitpunkten ablaufen und zum Zeitpunkt der Stichprobennahme bereits fertig sind. Verzerrungen ergeben sich auch, wenn das gesamte Programmlaufzeit recht kurz ist und nur wenige Stichproben genommen werden können. Zwar kann die Sampling-Rate in der Regel eingestellt werden, aber dennoch bleibt das Ergebnis bis zu gewissem Grad vom Zufall beeinflußt. Dafür hat diese Art der Datenerhebung den Vorteil, daß das Performance-Verhalten des gemessenen Programms nicht spürbar verändert wird.Bei der Instrumentierung wird der Eintritt in jede Methode und der Austritt aus jeder Methode erfaßt. Damit gehen, anders als bei den Stichproben, alle aufgerufenen Methoden präzise in die Zeitmessung ein. Für die Erfassung von Methodeneintritt und –austritt gibt es zwei Techniken. Die eine ist die Vorgehensweise über Callbacks, wie wir sie im vorangegangenen Artikel beschrieben haben: der Methodenein- und austritt sind Events, die den Aufruf einer Callback-Methode des Profiler-Agenten auslösen. Daneben gibt es die Byte Code Insertion (BCI), bei der der Bytecode selbst, typischerweise beim Laden der Klasse, geändert wird, indem zusätzliche Anweisungen für die Zeitmessung eingefügt werden. Auch die Byte Code Insertion wird über den Event-Callback-Mechanismus bewerkstelligt. Das Laden und Entladen sind nämlich ebenfalls Events, für die der Profiler Callback-Methoden einhängen kann. Ein solcher Callback kann beim Laden der Klasse den Bytecode der Klasse instrumentieren und in jede Methode Instruktionen einfügen, die den Eintritt und Austritt aus der Methode erfassen.
BCI ist heutzutage die Standardtechnik, mit der Profiler-Tools die Instrumentierung machen. Die Callback-Technik wurde in älteren HPROF-Versionen (vor Java 5.0) verwendet, weil die alte JVMPI-Schnittstelle die Byte Code Insertion nicht optimal unterstützt hat. Die neue JVMTI-Schnittstelle unterstützt BCI besser als früher und der HPROF in Java 5.0 nutzt diese Möglichkeit. Kommerzielle Tools haben auch schon vorher mit Byte Code Insertion gearbeitet, weil BCI tendenziell weniger Overhead erzeugt als die Callbacks (aber immer noch mehr als das Sampling). BCI ist schneller, weil die eingefügten Bytecode-Instruktionen in der Regel weniger Zeit brauchen, als die Erzeugung von Events für den Methodeneintritt und –austritt und der anschließende Aufruf der dazu registrierten Callback-Methoden. Wie groß der Unterschied zwischen Callback und Byte Code Insertion ist, hängt natürlich davon ab, was der eingefügte Bytecode tut.
Generell muss man sagen, daß sich die Instrumentierung negativ auf die Performance des zu messenden Programms auswirkt, weil nun plötzlich alle Methodenaufrufe langsamer werden. Das allein kann bei großen Anwendungen durchaus zum Problem werden; die Instrumentierung skaliert nicht. Zusätzlich muß man berücksichtigen, dass bei einer Instrumentierung wesentlich mehr Daten erfaßt werden als beim Sampling, so daß u.U. sehr große Messprotokolle entstehen.
Darüber hinaus kann die Instrumentierung die Messergebnisse verfälschen und läßt dann insbesondere kurze Methoden schlimmer aussehen, als sie wirklich sind. Das liegt daran, dass alle Methoden um denselben Mess-Overhead langsamer werden. In einer Liste, die die Methoden sortiert nach der Ablaufzeit jeder einzelnen Methode auflistet, tauchen alle Methoden noch in der richtigen Reihenfolge auf, weil der Overhead bei allen Methoden gleich ist. Zwei Methoden, die eigentlich 10 ms und 100 ms lang dauern, tauchen dann mit 15 ms bzw. 105 ms in der Liste auf, wenn der Mess-Overhead 5 ms beträgt. Wenn aber akkumulierte Werte berechnet werden, z.B. „durchschnittliche Ablaufzeit x Anzahl der Aufrufe“, dann sehen die eigentlich kurzen Methoden deutlich schlimmer aus, als sie in Wirklichkeit sind, weil der Mess-Overhead für eine kurze, häufig gerufene Methode eben häufiger mit in die Berechnung eingeht. Wenn die 10ms-Methode 10.000 mal und die 100ms-Methode 1.000 mal gerufen wird, dann sind die akkumulierten Werte für beide Methoden eigentlich gleich, nämlich 100 s. Mit dem Mess-Overhead taucht die 10ms-Methode aber akkumuliert mit 150 s in der Statistik auf, die 100ms-Methode aber nur noch mit 105 s. Man sieht also deutlich die Messwertverfälschung. Wie stark die Verzerrung ist, hängt von der gewählten Implementierungstechnik des Profilers ab (Callback oder BCI).
Mit der Auswahl zwischen Sampling und Instrumentierung hat man also
einen Trade-Off zwischen fehlender Präzision (bei den Stichproben)
und Messwertverfälschung plus Skalierungsproblemen (bei der Instrumentierung).
Die Stichproben sind sinnvoll, wenn ein Programm gemessen wird, das sehr
lange (z.B. über Nacht) läuft; die hohe Anzahl der Stichproben
kompensiert dann das Zufallsmoment. Die Instrumentierung ist sinnvoll,
wenn relativ kurz laufende Programme gemessen werden, oder solche die hauptsächlich
aus Methoden mit kurzen Laufzeiten (im 100 msec-Bereich) bestehen.
Such- und Optimierungsstrategie
Im Folgenden beschreiben wir die Vorgehensweise zum Aufspüren von Tuning-Kandidaten am Beispiel des HPROF zusammen mit HPjmeter Bei anderen Tool funktioniert es im Prinzip genauso, aber im Detail natürlich anders.
Im ersten Ansatz wird die Liste der exklusiven, akkumulierten CPU-Verbrauchswerte
(siehe Abbildung 1) angeschaut. Wenn eine Methode in dieser Liste ganz
oben steht, dann bedeutet es, daß die Methode entweder lang läuft
oder sehr oft gerufen wird oder beides. Eine solche Methode ist ein
aussichtsreicher Kandidat für ein erfolgreiches Performance-Tuning.
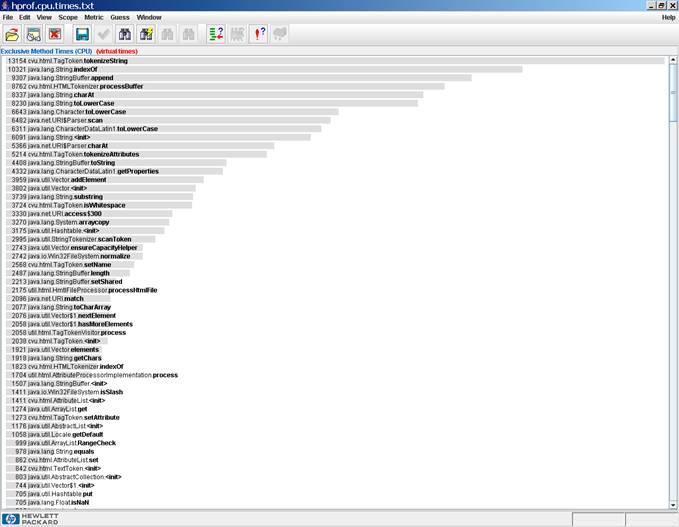
Abbildung 1: Exklusiver CPU-Verbrauch je Methoden (im HPjmeter)
[
größeres
Bild
]
In unserem Beispiel sind die vorderen Ränge dieser Liste mit Methoden
belegt, die entweder aus dem Java JDK (Packages java.lang, java.net, java.util,
etc.) oder aus einer Bibliothek (Package cvu.html) stammen. Die eigenen
Methoden (Package util.html) kommen erst sehr viel weiter unten in der
Liste. Für unsere Tuning-Anstrengungen ist das einerseits gut
und andererseits schlecht.
Es ist gut, weil keine unserer projekteigenen Methoden ein unübersehbares
Performance-Bottleneck darstellt. Es ist schlecht, weil wir jetzt
nicht wissen, wo wir mit dem Tuning ansetzen sollen. Methoden, die
aus dem JDK stammen, oder aus dem Webserver, dem ApplicationServer oder
aus irgendeinem verwendeten Framework, wollen und/oder können wir
nicht tunen. Eigentlich suchen wir nach Tuning-Kandidaten aus unserem
eigenen Projekt.
In einer solchen Situation sieht man sich die Liste der inklusiven CPU-Verbrauchswerte an. Hier finden sich in der Regel auch die Methoden der projekteigenen Klassen in den oberen Rängen wieder. Man sucht nun nach Methoden des eigenen Projekts, die einen hohen inklusiven CPU-Verbrauchswert haben und häufig aufgerufen werden. Um einen solchen projekteigenen Tuning-Kandidaten zu optimieren, schaut man in die Methode hinein und ermittelt, welche Methoden der Tuning-Kandidat seinerseits aufruft und welche von den aufgerufenen Methoden viel CPU-Zeit exklusiv in Anspruch nehmen.
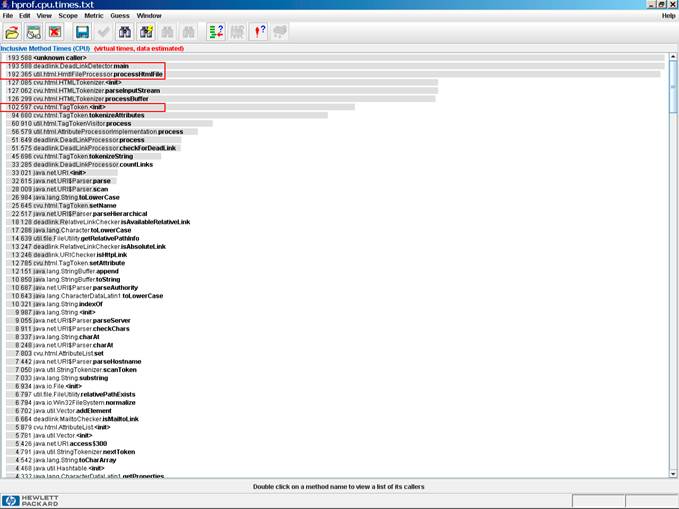
Abbildung 2: Inklusiver CPU-Verbrauch je Methoden (im HPjmeter)
[
größeres
Bild
]
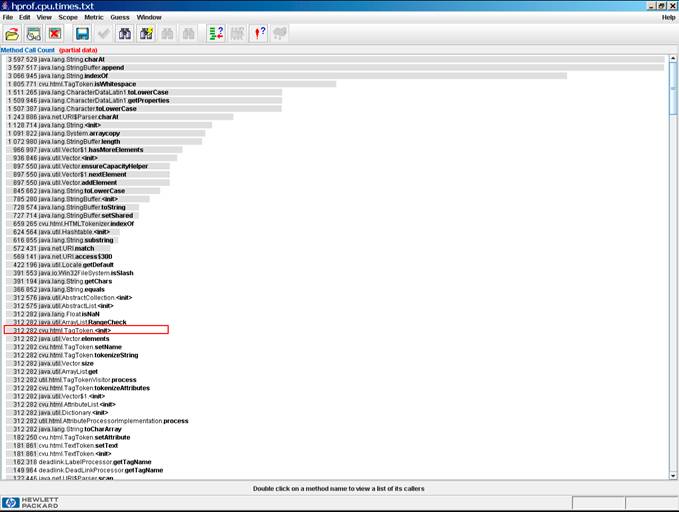
Abbildung 3: Aufrufhäufigkeit je Methode (im HPjmeter)
[
größeres
Bild
]
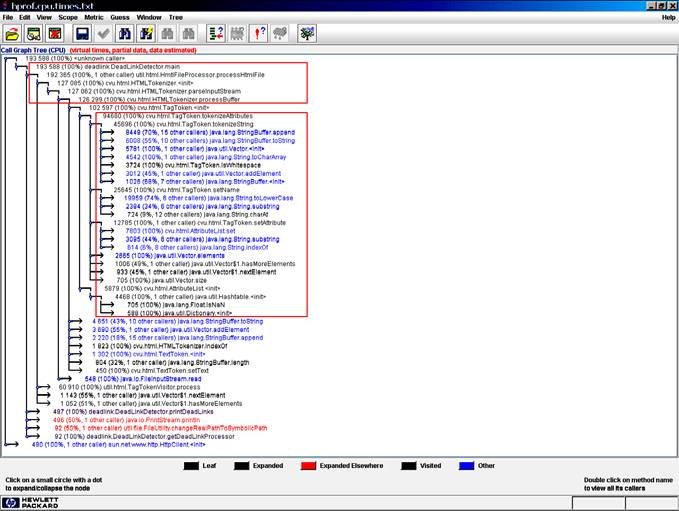
Abbildung 4: Dynamische Aufrufbeziehungen (im HPjmeter)
[
größeres
Bild
]
In unserem Beispiel springen in der Liste der inklusiven CPU-Verbrauchswerte (siehe Abbildung 2) die main-Methode und die Methode processHtmlFile ins Auge. Sie werden aber beide nicht gerade häufig aufgerufen. Wenn man die Liste der Aufrufhäufigkeiten (siehe Abbildung 3) daneben legt, sieht man, dass der Konstruktor der Klasse cvu.html.TagToken viel Zeit verbraucht und relativ häufig aufgerufen wird. Dieser Konstruktor wäre ein aussichtsreicher Tuning-Kandidat. Das bestätigt sich, wenn die Aufrufbeziehungen (siehe Abbildung 4) überprüft werden: es stellt sich nämlich heraus, dass der TagToken-Konstruktor genau die Methode aufruft, die Spitzenreiter in der Liste der exklusiven Methoden ist, nämlich die Methode cvu.html.TagToken.tokenizeString. Hier kann man nun ein Tuning versuchen, dass die Zahl der Aufrufe der „teuren“ tokenizeString-Methode reduziert.
Ganz allgemein hat eine Optimierungsstrategie also 3 Schritte: (a) man
identifiziert einen Tuning-Kandidaten, (b) schaut nach Tuningmöglichkeiten
im Inneren des Kandidaten und (c) dann nach Tuningmöglichkeiten in
der Umgebung des Kandidaten.
Im Schritt (b) wird versucht, den Tuning-Kandidaten durch performantere
Alternativen zu ersetzen. An dieser Stelle greift man auf jene Tuning-Tips
zurück, die man in Büchern und Artikeln für Java-Programmierer
findet. Zum Beispiel könnte man eine ungepufferte I/O durch
eine gepufferte I/O ersetzen, falls es um I/O geht. Oder man könnte
Arrays statt Collections verwenden, oder StringBuilder anstelle von StringBuffer,
usw. Es geht ganz allgemein gesprochen darum, einen besseren Algorithmus
zu finden.
Wenn es keine bessere Implementierung für die betroffene Methode gibt, dann sieht man sich in Schritt (c) die Methode von Außen an und schaut, ob sich vielleicht die Zahl der Aufrufe der Methode selbst reduzieren läßt, durch Umstrukturierungen an anderen Stellen im Programm.
CPU Time vs. Elapsed Time
Für das Auffinden von Kandidaten für ein Performance-Tuning haben wir die verbrauchte CPU-Zeit herangezogen. Das ist üblich und sinnvoll. Der HPROF bietet auch keine andere Möglichkeit, denn er ermittelt keine Elapsed Zeit. Manche Profiler-Tools ermitteln aber neben der CPU-Zeit auch noch die Elapsed-Zeit. Dann hat man die Gelegenheit, einen Vergleich von CPU- und Elapsed-Zeitangabe für die Methoden machen. Auch aus diesem Vergleich können Rückschlüsse auf Tuning-Potential oder Schwachstellen im Programm gezogen werden. Methoden, die eine erhebliche Differenz zwischen CPU- und Elapsed-Zeit aufweisen, verbringen offenbar sehr viel Zeit mit Warten – möglicherweise unnötig viel Zeit. Bei einer solchen Methode lohnt es sich nachzusehen, ob die Differenz absichtlich oder versehentlich zustande kommt. Es könnte beispielsweise sein, daß eine Methode viel Zeit mit Warten auf Locks oder Conditions verbringt, obwohl sie eigentlich vom Design her CPU-intensive Arbeiten machen sollte. Dann liegt vermutlich ein Fehler im Design der Verteilung von Aufgaben auf Threads, deren Synchronisation, usw. vor. Den Vergleich kann man auch auf ganze Threads bzw. die gesamte Anwendung ausdehnen.Zusammenfassung
In diesem Beitrag haben wir angefangen, verschiedene Profiling-Aktivitäten zu erläutern. Wir haben nach Performance-HotSpots gesucht, also nach Methoden, die sehr viel Zeit verbrauchen und/oder sehr oft aufgerufen werden und überlegt, wie man solche Schwachstellen beseitigen kann. Im nächsten Beitrag suchen wir nach Memory HotSpots und Memory Leaks.Literaturverweise und weitere Informationsquellen
| /PERF/ |
Java Performance
Informationen zu Performance von Sun. URL: http://java.sun.com/docs/performance/ |
| /JVMPI/ |
JavaTM Virtual Machine Profiler Interface (JVMPI)
URL: http://java.sun.com/j2se/1.4.2/docs/guide/jvmpi/jvmpi.html |
| /JVMTI/ |
Creating a Debugging and Profiling Agent with JVMTI
URL: http://java.sun.com/developer/technicalArticles/Programming/jvmti/ |
| /TRANS/ |
The JVMPI Transition to JVMTI
URL: http://java.sun.com/developer/technicalArticles/Programming/jvmpitransition/#1 |
| /TUNE/ |
Java Performance Tuning
Ein Überblick über vermutlich die meisten verfügbaren Profiler Tools zum Teil mit Beschreibung und Bewertung. URL: http://www.javaperformancetuning.com/resources.shtml URL: http://www.javaperformancetuning.com/tools/index.shtml |
| /HPROF/ |
HPROF: A Heap/CPU Profiling Tool in J2SE 5.0
Ein Artikel über die neue HPROF-Architektur in Java 5.0 vom November 2004. URL: http://java.sun.com/developer/technicalArticles/Programming/HPROF.html
Java Performance Tuning and Memory Management
Tool Report: Hpjmeter
|
| /HPJM/ |
HPjmeter 1.6
Die Toolseite von Hewlett-Packard mit Download und Informationen. URL: http://www.hp.com/products1/unix/java/hpjmeter/index.html
Tool Report: HPjmeter
|
| /ECOL/ |
Eclipse Colorer
Ein PlugIn für das Profiling von Anwendungen in Eclipse. URL: http://sourceforge.net/projects/eclipsecolorer |
Die gesamte Serie über Java Performance:
| /KRE1/ |
Java Performance, Teil 1: Was ist ein Micro-Benchmark?
Klaus Kreft & Angelika Langer Java Spektrum, Juli 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/21.MicroBenchmarking/21.MicroBenchmarking.html |
| /KRE2/ |
Java Performance, Teil 2: Wie wirkt sich die HotSpot-Technologie
aufs Micro-Benchmarking aus?
Klaus Kreft & Angelika Langer Java Spektrum, September 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/22.JITCompilation/22.JITCompilation.html |
| /KRE3/ |
Java Performance, Teil 3: Wie funktionieren Profiler-Tools?
Klaus Kreft & Angelika Langer Java Spektrum, November 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/23.ProfilingTools/23.ProfilingTools.html |
| /KRE4/ |
Java Performance, Teil 4: Performance Hotspots - Wie findet man
funktionale Performance Hotspots?
Klaus Kreft & Angelika Langer Java Spektrum, Januar 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/24.FunctionalHotSpots/24.FunctionalHotSpots.html |
| /KRE5/ |
Java Performance, Teil 5: Performance Hotspots - Wie findet man
Memory Hotspots?
Klaus Kreft & Angelika Langer Java Spektrum, März 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/25.MemoryHotSpots/25.MemoryHotSpots.html |
| /KRE6/ |
Java Performance, Teil 6: Garbage Collection - Wie funktioniert
Garbage Collection?
Klaus Kreft & Angelika Langer Java Spektrum, Mai/Juli 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/26.GarbageCollection/26.GarbageCollection.html |
| /KRE7/ |
Java Performance, Teil 7: Garbage Collection - Das Tunen des Garbage
Collectors
Klaus Kreft & Angelika Langer Java Spektrum, September 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/27.GCTuning.html/27.GCTuning.html |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||
Seminar
|
||