| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java Performance: Micro-Benchmarking
Wie wirkt sich die HotSpot-Technologie
aufs Micro-Benchmarking aus?
JavaSPEKTRUM, September 2005
|
Dies ist das Manuskript eines Artikels, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im JavaSPEKTRUM erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Micro-Benchmarks sind Vergleichsmessungen, bei denen die Performance
verschiedener, alternativer Algorithmen gemessen und anschließend
verglichen wird, um den besseren (d.h. schnelleren) Algorithmus zu bestimmen.
Solche Messungen werden zum Beispiel im Rahmen von Tuningmaßnahmen
gemacht. Das Aufsetzen eines solchen Micro-Benchmarks ist keineswegs
trivial. Zwar liefert ein Benchmark immer ein Ergebnis, aber das
Ergebnis ist u.U. ohne jede Aussagekraft oder sogar grob irreführend,
weil der Benchmark fehlerhaft ist. Einige der Fehlerquellen haben
wir im letzten Artikel bereits diskutiert. Dabei haben wir erwähnt,
daß die HotSpot-Technologie aussagekräftige Performance-Messungen
erheblich erschwert. In diesem Beitrag wollen wir uns näher
ansehen, warum das so ist und worauf beim Micro-Benchmarking mit einer
HotSpot-JVM geachtet werden muß.
Hot Spot Optimierung
Java funktioniert prinzipiell so, daß die Virtuelle Maschine zur Laufzeit den sogenannten Java Byte Code interpretiert, den der Compiler aus dem Java Source Code erzeugt hat. Bei den HotSpot-Optimierungen geht es darum, daß die Virtuelle Maschine während des Programmablaufs ein Profiling durchführt, um besonders häufig durchlaufene Programmteile zu identifizieren – die sogenannten Hot Spots. Für diese Hot Spots werden dann während des Programmablaufs Optimierungen durchgeführt. Die Optimierung besteht darin, daß der HotSpot in die Maschinensprache der betreffenden Plattform übersetzt wird. Das bezeichnet man als Just-In-Time-Compilierung. Daher stammt auch der Begriff JIT-Compiler (JIT = Just In Time). Die HotSpot-Technik wurde nämlich anfangs unter dem Begriff JIT-Compilation eingeführt; später hat sich der Begriff HotSpot-Optimierung durchgesetzt.HotSpot-Optimierungen machen erhebliche Probleme, wenn man zum Zweck einer vergleichenden Performance-Messung einen Micro-Benchmark aufsetzen will. Man weiß nämlich nicht, wann die HotSpot-Optimierung zuschlägt und was sie dann eigentlich bewirkt. Wenn das zu messende Code-Stück in seiner nicht-optimierten Form vermessen wird, dann ergeben sich ganz andere (nämlich schlechtere) Meßwerte, als wenn die Messung nach einer HotSpot-Optimierung vor sich geht. Es kann auch passieren, daß der Vorgang der Optimierung selbst, der ja Zeit kostet, in die Messung einbezogen wird und das Ergebnis verfälscht. Es kann auch vorkommen - und das ist gar nicht selten - daß das zu messende Code-Stück nach der Optimierung gar nicht mehr da ist, weil es einer Dead-Code-Elimination zum Opfer gefallen ist. Der Programmierer muß sich also erst einmal mit der HotSpot-Technologie vertraut machen, ehe er einen sinnvollen Micro-Benchmark aufsetzen kann.
Nun ist es in der Praxis leider so, daß die Details der HotSpot-Technologie abhängig sind von der Implementierung der jeweiligen Virtuellen Maschine. Die HotSpot-Technologie gehört, ähnlich wie die Garbage Collection, nicht zum standardisierten und spezifizierten Teil von Java und seiner Ablaufumgebung. Das heißt, jeder JVM-Hersteller macht, was er will. Der Programmierer ist deshalb angewiesen auf spärlichen Informationen, die die JVM-Hersteller über die Arbeitsweise ihrer jeweiligen JVM zur Verfügung stellen. Eine systematische, vollständige Beschreibung der HotSpot-Optimierung gibt es unseres Wissen zu keiner einzigen JVM.
Es gibt sporadisch Information von Sun Microsystems (siehe /PERF/). Daraus kann man ablesen, daß die Regeln für die HotSpot-Optimierungen kontext-abhängig und komplex sind und sich dazu noch gegenseitig überlagern. Das heißt, selbst in Kenntnis der Optimierungsregeln ist es schwer vorherzusagen, welche Optimierungen unter welchen Umständen vorgenommen werden. Das macht es äußerst schwierig, die Auswirkungen der HotSpot-Optimierungen auf einen Micro-Benchmark zu beurteilen.
Im folgenden wollen wir einige der Schwierigkeiten diskutieren und ein paar Faustregeln für einen erfolgreichen Micro-Benchmark daraus ableiten. Dabei haben wir unterstellt, daß die Techniken, die in den JVMs von Sun Microsystems verwendet werden, ähnlich auch in anderen Virtuellen Machinen Anwendung finden. Um aber sicherzugehen, sollte die Dokumentation, falls vorhanden, der jeweils verwendeten JVM konsultiert werden.
Beginnen wir mit einem Beispiel, das die Schwierigkeiten illustriert.
Inlining von Methoden
Vor der Erfindung der HotSpot-Optimierung gab es eine einfache Regel: für public non-final Methoden wird kein Inlining gemacht. Das liegt daran, daß solche Methoden in Subklassen überschrieben sein könnten und der Aufruf der Methoden polymorph ist, d.h. es wird nicht zur Compile-Zeit, sondern erst zur Laufzeit abhängig von dynamischer Typinformation entschieden, welche Version der Methode tatsächlich gerufen wird. Es ist nicht möglich, ein einmaliges Inlining für einen Methodenaufruf zu machen, wenn jedesmal ein andere Version der Methode gerufen wird. Damit war die Optimierung per Inlining für public non-final Methoden in einer JVM ohne HotSpot-Technik ausgeschlossen.Bei einer HotSpot JVM ist das anders. Die Virtuelle Maschine sammelt während des Programmablaufs globale Informationen über die Methodenaufrufe. Wenn dabei festgestellt wird, daß eine public non-final Methode gar nicht polymorph genutzt wird, dann wird ein Inlining gemacht, auch als Monomorphic-Call-Transformation bezeichnet. Nun kann es aber sein, daß die betreffende Methode später, nach der Inline-Optimierung, doch noch polymorph genutzt wird, weil andere Teile des Codes durchlaufen werden, wo polymorphe Aufrufe gemacht werden. Dann muß das Inlining wieder rückgängig gemacht werden. Dieses Rückgängigmachen führt zu einer temporären Verschlechterung (Pessimierung), weil der Methodenaufruf, der das Rückgängigmachen auslöst hat, ganz besonders langsam ausfällt.
Hier ein Beispiel, bei dem die Pessimierung durch das Inlining sichtbar wird:
public abstract class A {Die Ergebnisse sehen typischerweise so aus:
public static double x = 2.0;
abstract void aMethod();
}
public class B extends A {
public void aMethod() { x = x + 1.1; }
}
public class C extends A {
public void aMethod() { x = x - 1.1; }
}
public class D extends A {
public void aMethod() { x = x + 2.2; }
}
public final class Benchmark {
private static void test(A bar) {
long starttime = System.currentTimeMillis();
for (int i = 0; i < 5000000; i++)
bar.aMethod();
long endtime = System.currentTimeMillis();
System.out.println("elapsed milli-seconds: "
+ (endtime - starttime));
}
public static void main(String[] args) {
A b = new B();
A c = new C();
A d = new D();
test(b); // warmup foo
test(b); test(c); test(d);
}
}
elapsed milli-seconds: 170 ( B – Aufwärmphase )Hier wird in der test Methode die polymorphe Methode aMethod zunächst in einer Aufwärmphase 5.000.000 mal angestoßen, wobei in allen Fällen die Version der Klasse B gerufen wird. Die an sich polymorphe Methode aMethod wird also monomorph verwendet. Die JVM macht daraufhin ein Inlining; die nächsten 5.000.000 Aufrufe sind auch deutlich schneller. Wenn dann aber plötzlich in der test Methode die Methode aMethod der Klasse C gerufen wird, dann liegt eine polymorphe Nutzung vor und das Inlining muß rückgängig gemacht werden. Das wird in dem schlechten Meßwert für die Aufrufe von C.aMethod sichtbar. Danach liegt die Performance der Aufrufe wieder im dem Bereich vor der Optimierung.
elapsed milli-seconds: 20 ( B )
elapsed milli-seconds: 230 ( C )
elapsed milli-seconds: 180 ( D )
Das Benchmarking wird durch die Inlining-Strategie der HotSpot JVM erschwert. Wenn man eine Methode, die dem Inlining unterzogen wird, bzgl. ihrer Performance messen will, dann hängt das Meßergebnis davon ab, in welchem Stadium die Methode erwischt wird: „optimiert“ per Inlining, „pessimiert“ wegen des Rückgängigmachens, oder „normal“ ohne jegliche Optimierung. Es ist unter diesen Umständen äußerst schwierig, eine aussagekräftige Messung zu machen.
So gesehen hat die HotSpot-Technologie positive, aber auch negative Effekte: sie führt tendenziell zu Performance-Verbesserungen, aber gleichzeitig entzieht sie dem Programmierer die Kontrolle über die Performance seines Programms. Kann man unter diesen Umständen überhaupt sagen, worauf man achten muß, um ein aussagekräftiges Benchmarking zu machen?
Regeln für Micro-Benchmarks
Ums gleich vorweg zu sagen: klare Regeln für HotSpot-Optimierungen, die man in die Meßstrategie einbeziehen könnte, gibt es nicht. Das liegt wie schon erwähnt daran, daß Optimierungen immer implementierungsspezifisch sind und von JVM zu JVM unterschiedlich sein können. Zudem wird die HotSpot-Technologie ständig weiterentwickelt und so kommen fortlaufend neue Optimierungsstrategien hinzu. Die Strategien der jüngsten JVM-Generation sind extrem kontext-abhängig, d.h. sie hängen stark vom tatsächlich durchlaufenen Code ab.Man kann einige wenige, vage Regeln aufstellen, die sich aus der prinzipiellen Arbeitsweise einer HotSpot JVM ergeben. Eine HotSpot JVM arbeitet so, daß sie die Häufigkeit der Aufrufe einer Methode feststellt. Sobald ein Schwellenwert erreicht ist, wird die Methode kompiliert und dabei optimiert. Danach wird in regelmäßigen Abständen nachjustiert und ggf. rekompiliert und noch weiter optimiert, bis die HotSpot JVM nach einer Weile mit den Rekompilierungen aufhört, weil die Methode nun in ihrer optimalen Form vorliegt.
Daraus kann man einige Regeln ableiten:
Inline-Optimierung der Benchmark-Methoden vermeiden
Wir haben oben ein Beispiel gesehen, in dem die Inline-Optimierung (bzw. Monomorphic-Call-Transformation) illustriert und die resultierende Verzerrung der Meßergebnisse gezeigt wurde. Nun werden solche Optimierung sowohl für die Methoden des zu messenden Algorithmus gemacht (im Folgenden „Testling“ genannt) als auch für die Methoden des Micro-Benchmarks selbst. Der Micro-Benchmark ist, genau wie der Testling, ein Stück Source-Code, das die JVM analysiert und optimiert. Beim Aufsetzen des Micro-Benchmark muß deshalb darauf geachtet werden, daß nicht die Methoden des Benchmarks selbst der Inline-Optimierung zum Opfer fallen. Leider kann das sehr leicht passieren. Sehen wir uns ein Negativ(!)-Beispiel an:interface Algorithm { void doIt(); }Die Idee hier ist die folgende: es sollen zwei alternative Algorithmen verglichen werden. Der Autor dieses Benchmarks hat dazu zwei Klassen definiert und in jeder dieser beiden Klassen jeweils eine Variante des betreffenden Algorithmus implementiert. Der Testtreiber ruft beide Varianten über ein gemeinsames Interface auf.
class Algorithm_1 implements Algorithm { ... }
class Algorithm_2 implements Algorithm { ... }
class MicroBenchmark {
private static long test(Algorithm alg) {
long start = System.nanoTime();
for(long i = 0; i < 10000000L; i++) alg.doIt();
return System.nanoTime() - start;
}
public static void main(String[] args) {
long time_1 = test(new Algorithm_1());
long time_2 = test(new Algorithm_2());
... print statistics ...
}
}
Vom Design her sieht das gut aus, aber für einen Micro-Benchmark ist es schlecht. Man wird nämlich beobachten, daß immer derjenige Algorithmus schneller ist, der als erster aufgerufen wird. Das liegt an der Inline-Optimierung. Während die Schleife für den ersten Algorithmus abläuft, ist der Aufruf der Methode doIt() immer monomorph und deshalb wird die Monomorphic-Call-Transformation gemacht. Wenn die zweite Variante abläuft, stellt die JVM fest, daß der Aufruf von doIt()doch polymorph ist, und macht die Optimierung wieder rückgängig. Der zweite Algorithmus wird also langsamer aussehen als der erste, nicht weil er tatsächlich langsamer ist, sondern weil er nicht optimiert ist.
Man kann aus dieser Beobachtung nun ableiten, daß Testlinge nicht
über polymorphe Aufrufe (wie hier über ein Interface) angestoßen
werden sollten. Man kann aber auch alternativ dafür sorgen,
daß beide Testlinge in nicht-optimierter Form gemessen werden.
Das könnte man erreichen, indem vor der eigentlichen Messung beide
Methoden hinreichend oft im Wechsel gerufen werden, damit die JVM merkt,
daß hier eine polymorphe Methode vorliegt und ein Inlining keinen
Sinn macht. Ob die JVM das mitkriegt, kann mit Hilfe der –XX:+PrintCompilation
Option überprüft werden. Zumindest bei den Sun-JVMs gibt
es diese Option. Sie führt dazu, daß die Virtuelle Maschine
Informationen darüber ausgibt, welche Methoden einer Optimierung oder
Pessimierung unterzogen wurden. An den Ausgaben kann man verifizieren,
daß die doIt() Methode erst optimiert und dann pessimiert wird.
Erst wenn die doIt() Methode in den Ausgaben nicht mehr auftaucht, sollte
die eigentliche Messung einsetzen.
Aufwärmphase
Die Idee der HotSpot-Optimierung ist, daß die Virtuelle Maschine während des Programmablaufs mitzählt, wie oft jede Methode aufgerufen wird, um auf diese Weise die HotSpots (d.h. die besondern häufig aufgerufenen Methoden) zu identifizieren. Das heißt, all die Optimierungen setzen erst ein, wenn die Aufrufhäufigkeit einer Methode einen gewissen Schwellenwert erreicht hat. Danach wird die Methode periodisch weiter optimiert, oder auch pessimiert, bis nach einer gewissen Zeit nichts mehr mit der Methode gemacht wird, weil sie ihren optimalen Zustand erreicht hat.Während dieser Optimierungen und Re-Optimierungen sollten keine Messungen gemacht werden, weil man nicht weiß, was eigentlich genau gemessen wird: die Methode in optimierter Form oder in nicht-optimierter Form, oder wird gar der Overhead der Optimierung mit erfaßt? Sinnvoller ist es zu warten, bis die zu messenden Methoden ihren Endzustand erreicht haben, ehe die eigentlichen Messungen gemacht werden. Ein Micro-Benchmark sollte also in der Regel eine Aufwärmphase haben, in der die zu messende Methode so häufig gerufen wird, bis die Methode optimiert und ihren endgültigen Zustand gebracht wurde.
Wie lang nun diese Aufwärmphase sein muß, läßt sich nicht so ohne weiteres bestimmen. Bei älteren JIT-Compilern war das noch relativ einfach. Es gab einen Schwellenwert, bei dem die Optimierung einsetzte. Als Faustwert wurde ein Wiederholungsfaktor von 100.000 angesehen. Die JVM hat auch nicht sehr viel re-optimiert, so daß relativ leicht zu bestimmen war, wie lang eine Aufwärmphase sein mußte. Die jüngeren JIT-Compiler verhalten sich wesentlich weniger absehbar. Das liegt an den komplexeren Optimierungsstrategien und der größeren Kontextabhängigkeit. Ein einfacher Schwellenwert läßt sich nicht mehr feststellen.
Man bestimmt die Länge der Aufwärmphase deshalb so wie bereits oben angedeutet. Man läßt die zu messenden Methoden mit einem hohen Wiederholungsfaktor laufen und beobachtet die Ausgaben der JVM, die man mit der –XX:+PrintCompilation Option gestartet hat. Anfangs wird man eine ganze Menge Ausgaben sehen. Irgendwann beruhigt sich die JVM und es kommen keine Ausgaben mehr. Dann ist die JVM mit den Optimierungen fertig und die Messung kann beginnen. Die so ermittelten Aufwärmphasen können unterschiedlich lang sein. Das hängt ganz vom Kontext ab und es gibt keinen absehbaren fixen Schwellenwert mehr in modernen JVMs.
Bleibt also festzuhalten: ein Micro-Benchmark hat in der Regel eine
Aufwärmphase. Wobei man diese Regel auch wieder relativieren
muß. Wenn die Messung die Performance eines Algorithmus nach
einer Wiederholung von 1.000.000 Aufrufen widerspiegelt, dann muß
man sich schon fragen, ob das überhaupt realistisch ist. Wird
der Algorithmus in der echten Anwendung überhaupt so oft aufgerufen?
Das kann sein, wenn es sich um eine Server-Applikation handelt, die rund
um die Uhr ohne Unterbrechung läuft. Das muß aber keineswegs
in allen Anwendungen so sein. Wenn die gemessene Methode in der echten
Umgebung im Durchschnitt nur 10.000 mal gerufen wird, ehe die Anwendung
neu gestartet wird, dann ist die Performance, die nach 1.000.000 Aufrufen
erreicht wird, irrelevant, weil sie in der realen Umgebung gar nicht erreicht
wird. Die Umgebung, die der Micro-Benchmark für die Performance-Messung
herstellt, sollte immer die Gegebenheiten der echten Umgebung in der Applikation
möglichst gut nachbilden.
Testfall wegoptimiert
Ein weiteres Problem ist die sogenannte Dead-Code-Elimination. Das ist eine Optimierung, die bereits vom Compiler gemacht werden kann. Wenn festgestellt wird, daß ein bestimmtes Code-Segment gar nichts tut, d.h. kein Ergebnis produziert oder ein Ergebnis produziert, das nicht verwendet wird, dann kann das gesamte Code-Segment eliminiert werden. Das ist eine sinnvolle Optimierung. Dummerweise schlägt sie besonders häufig in Micro-Benchmarks zu.Beim Micro-Benchmark soll eine bestimmte Funktionalität gemessen werden. Also wird man möglichst nur die zu messende Funktionalität ausführen, und sonst nichts, weil andere Aktivitäten ins Meßergebnis eingehen würden und dies verfälschen könnten. Mit anderen Worten, es ist relativ naheliegend, daß ein Micro-Benchmark nichts tut, absehen von der fraglichen Funktionalität, deren Ergebnis aber auch nicht verarbeitet wird, wenn denn überhaupt ein Ergebnis produziert wurde. Das heißt, ein Micro-Benchmark tut unter Umständen nichts Sinnvolles. Genau in dieser Situation schlägt die Dead-Code-Eliminierung zu und führt dazu, daß die zu messende Funktionalität komplett wegoptimiert ist.
Hier ein Beispiel:
public final class Test extends Thread {Das Ergebnis der Berechnung in der obigen run()-Methode wird nicht verwendet und die gesamte Berechnung kann deshalb wegoptimiert werden. Hier wird also lediglich das Starten und Beenden von Threads gemessen und nicht, wie beabsichtigt, die Performance der Berechnung.
public void run() {
double d;
for (int i=0; i<1000; i++) {
for (int j=0;j<1000; j++) {
d = 3.0*(double)i*(double)i+7.0*j;
}
}
}private static void runBenchmark(int numberOfThreads) {
Thread[] threads = new Thread[numberOfThreads];
for (int indx=numberOfThreads; --indx >= 0; )
threads[indx] = new Test();System.out.println("--- "+numberOfThreads+" threads ---");
long starttime = System.currentTimeMillis();
for (int indx=numberOfThreads; --indx >= 0; ) {
threads[indx].start();
threads[indx].join();
}
long endtime = System.currentTimeMillis();
System.out.println("elapsed milli-seconds: " + (endtime - starttime));
}public static void main(String[] args) {
runBenchmark(1);
runBenchmark(10);
runBenchmark(100);
runBenchmark(1000);
}
}
Ähnliche "Wegoptimierungen" können passieren, wenn ein Constant-Folding oder ein Loop-Unrolling gemacht wird. Beim Constant-Folding wird ein Ausdruck, in dem nur Konstanten vorkommen, bereits zur Compile-Zeit berechnet und durch das Ergebnis der Berechnung ersetzt. Beim Loop-Unrolling wird eine Schleife durch die Wiederholung der Code-Sequenz ersetzt. Das ist eine Optimierung, die die JVM sogar dynamisch macht, wenn sie feststellt, daß die Schleife ein HotSpot ist. Hier ein Beispiel, in dem die arithmetische Berechnung, deren Performance offenbar gemessen werden soll, vermutlich wegoptimiert wurde:
long starttime = System.currentTimeMillis();
long sum = 0;
for (int indx=200000; --indx >= 0; ) sum +=
42;
long endtime = System.currentTimeMillis();
System.out.println("elapsed milli-seconds: "
+ (endtime - starttime));
Der Compiler kann hier bereits erkennen, daß sum nach der Schleife
den Wert 8.200.000 hat und wird vermutlich die gesamte Berechnung eliminieren.
Varianz der Meßwerte
Generell empfiehlt es sich, mehrere Messungen mit unterschiedlichen Wiederholungsfaktoren oder unter verschiedenen Bedingungen zu machen, um ein Gefühl für die Varianz der Meßwerte zu bekommen. Am einfachsten ist es natürlich, eine einzige Messung mit einem sehr hohen Wiederholungsfaktor zu machen und dann den Mittelwert als Meßwert für die Performance des Testlings zu betrachten. Wenn die Meßwerte aber stark schwanken, dann hat der Mittelwert keine große Aussagekraft.Schwankungen werden zum Beispiel dann auftreten, wenn die Messung noch während der Optimierungsphase vorgenommen wird, oder weil die Garbage Collection die Meßwerte beeinflußt, oder weil das Betriebssystem mit anderen Tätigkeiten belastet ist, die die Meßwerte beeinflussen. Zum Teil kann man sich Informationen über die Aktivitäten der JVM während der Messung verschaffen: durch die schon erwähnte -XX:+PrintCompilation Option, die Auskunft über die Optimierungen des JIT-Compilers gibt, oder über die –verbose:GC Option, die zu jeder Garbage Collection u.a. ausgibt, wie lange diese gedauert hat. Die Verwendung dieser Schalter kostet natürlich auch Performance. Man würde also einen ersten Lauf mit eingeschalteten Ausgaben machen, um die Aktivitäten zu sehen, und einen zweiten ohne die Ausgaben, um die tatsächliche Messung vorzunehmen.
Auf jeden Fall ist es sinnvoll, mehrere Messungen mit unterschiedlichen
Wiederholungsfaktoren zu machen und ggf. auch andere relevante Einflüsse
einzubeziehen, damit man ein Gefühl für die Schwankungen bekommt.
Sobald die Meßdaten vorliegen, kann man überlegen, wo in diesem
Spektrum der typische Anwendungsfall liegt, dessen Performance gemessen
werden sollte.
Client vs. Server JVM
Über eine Option (-server oder -client) kann beim Starten einer JVM angegeben werden, ob ein Server- oder ein Client-Programm gestartet wird und das hat Auswirkungen auf die Optimierungsstrategien, die die JVM anwendet. Genauer gesagt werden abhängig von dieser Option unterschiedliche Implementierungen der JVM gestartet, die sogenannte Client- oder Server-JVM. In Java 1.4 wird defaultmäßig eine Client-JVM gestartet; in Java 5.0 hängt der Default vom Betriebssystem und der Hardware-Ausstattung ab (siehe /DET/). Wenn eine HotSpot JVM mit der Option -server gestartet wurde, dann optimiert sie wesentlich aggressiver als eine Client-JVM, d.h. mit mehr Aufwand und höheren Kosten. Das lohnt sich, weil ein Server-Programm typischerweise länger läuft und sich deshalb die Optimierungen langfristig positiv auswirken, auch wenn kurzfristig die Performance-Verluste durch die Optimierung selbst höher sind.Betrachten wir noch einmal das Beispiel, das wir schon im Zusammenhang mit der Dead-Code-Eliminierung gesehen haben:
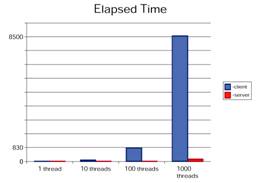
public final class Test extends Thread {Wenn man die run() Methode in unterschiedlich vielen Threads ausführt und die Performance dieser Ausführung mißt, stellt man fest, daß das es erhebliche Unterschiede zwischen der Client und Server JVM gibt. Insbesondere bei 1000 Threads ist der Unterschied gravierend.
public void run() {
double d;
for (int i=0; i<1000; i++) {
for (int j=0;j<1000; j++) {
d = 3.0*(double)i*(double)i+7.0*j;
}
}
}private static void runBenchmark(int numberOfThreads) {
Thread[] threads = new Thread[numberOfThreads];
for (int indx=numberOfThreads; --indx >= 0; )
threads[indx] = new Test();System.out.println("--- "+numberOfThreads+" threads ---");
long starttime = System.currentTimeMillis();
for (int indx=numberOfThreads; --indx >= 0; )
threads[indx].start();
long endtime = System.currentTimeMillis();
System.out.println("elapsed milli-seconds: " + (endtime - starttime));
}public static void main(String[] args) {
runBenchmark(1);
runBenchmark(10);
runBenchmark(100);
runBenchmark(1000);
}
}
|
|
Das liegt an den unterschiedlichen Optimierungsstrategien. Die Server JVM macht eine Dead-Code-Eliminierung, die Client JVM nicht.
Beim Micro-Benchmark muß also die HotSpot JVM (Client oder Server)
für die Messung gewählt werden, die auch in der realen Anwendung
verwendet würde
Zusammenfassung
Bei einem Micro-Benchmark wird versucht, die Essenz verschiedener alternativer Implementierungen in je einem kleinen Programmstück zu erfassen und die Performance dieser alternativen Implementierungen zu messen und zu vergleichen. Es ist schwierig, einen Micro-Benchmark zu schreiben, der aussagekräftige Meßergebnisse liefert. Schwierigkeiten machen dabei die HotSpot-Optimierungen, die der JIT-Compiler der Virtuellen Maschine während der Messung durchführt, denn diese Optimierungen beeinflussen die Meßwerte. Wir haben in diesem Artikel einige Aspekte der HotSpot-Technologie erläutert und daraus Empfehlungen für die Implementierung von Micro-Benchmarks abgeleitet:- Der Micro-Benchmark braucht eine Aufwärmphase.
- Es muß darauf geachtet werden, daß der Testling nicht durch Dead-Code-Eliminierung wegoptimiert oder durch Inline-Optimierung verzerrt wird.
- Client und Server JVM optimieren anders und führen zu anderen Meßergebnissen.
Literaturverweise und weitere Informationsquellen
| /PERF/ |
Java Performance
URL: http://java.sun.com/docs/performance/ |
| /HOT/ |
Java HotSpot VM Options 1.4
URL: http://java.sun.com/docs/hotspot/VMOptions.html |
| /DET/ |
Server-Class Machine Detection in 5.0
URL: http://java.sun.com/j2se/1.5.0/docs/guide/vm/server-class.html |
| /GOE1/ |
Dynamic compilation and performance measurement - The perils of
benchmarking under dynamic compilation
Brian Goetz IBM Developer Works, Dezember 2004 URL: http://www-106.ibm.com/developerworks/library/j-jtp12214/ |
Die gesamte Serie über Java Performance:
| /KRE1/ |
Java Performance, Teil 1: Was ist ein Micro-Benchmark?
Klaus Kreft & Angelika Langer Java Spektrum, Juli 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/21.MicroBenchmarking/21.MicroBenchmarking.html |
| /KRE2/ |
Java Performance, Teil 2: Wie wirkt sich die HotSpot-Technologie
aufs Micro-Benchmarking aus?
Klaus Kreft & Angelika Langer Java Spektrum, September 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/22.JITCompilation/22.JITCompilation.html |
| /KRE3/ |
Java Performance, Teil 3: Wie funktionieren Profiler-Tools?
Klaus Kreft & Angelika Langer Java Spektrum, November 2005 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/23.ProfilingTools/23.ProfilingTools.html |
| /KRE4/ |
Java Performance, Teil 4: Performance Hotspots - Wie findet man
funktionale Performance Hotspots?
Klaus Kreft & Angelika Langer Java Spektrum, Januar 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/24.FunctionalHotSpots/24.FunctionalHotSpots.html |
| /KRE5/ |
Java Performance, Teil 5: Performance Hotspots - Wie findet man
Memory Hotspots?
Klaus Kreft & Angelika Langer Java Spektrum, März 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/25.MemoryHotSpots/25.MemoryHotSpots.html |
| /KRE6/ |
Java Performance, Teil 6: Garbage Collection - Wie funktioniert
Garbage Collection?
Klaus Kreft & Angelika Langer Java Spektrum, Mai/Juli 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/26.GarbageCollection/26.GarbageCollection.html |
| /KRE7/ |
Java Performance, Teil 7: Garbage Collection - Das Tunen des Garbage
Collectors
Klaus Kreft & Angelika Langer Java Spektrum, September 2006 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/27.GCTuning.html/27.GCTuning.html |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||
Seminar
|
||