| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Memory Leaks
Ein Beispiel
Java Magazin, August 2012
|
Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
Unsere Reihe über Java 7 Neuerungen haben wir mit dem letzten Artikel abgeschlossen. Da sich Oracle mit Java 8 noch ein wenig Zeit lässt (als anvisierter Freigabe-Termin wird im Augenblick „Sommer 2013“ genannt), wollen wir die Gelegenheit nutzten, um noch einmal an die Artikelserie über Garbage Collection aus den Jahren 2010/2011 anzuschließen. Wir hatten damals die Garbage Collection in der HotSpot-JVM von Sun/Oracle sowie ihr Tuning detailliert besprochen. Bei Interesse kann man diese Artikel weiterhin auf unserer Webseite (/ ARGC /) oder zusammengefasst als Buch (/ JCP /) finden. Wir wollen anknüpfend an dieses zurückliegende Thema diskutieren, wie es zu Memory Leaks in Java kommen kann und wie man sie finden oder besser schon von vornherein vermeiden kann.
Was ist in Java ein Memory Leak?
|
Es stimmt schon: Memory Leaks wie in C/C++,
die auf Grund von vergessenem
free()
bzw.
delete
entstehen, gibt es in Java glücklicherweise nicht mehr. Das hat den
Vorteil, dass Memory Leaks in Java deutlich seltener auftreten als in C/C++.
[1]
Der
Nachteil ist, dass Memory Leaks in Java meist keine Flüchtigkeitsfehler
bei der Programmierung sind, sondern häufig eher Konzept- bzw. Designfehler.
|
[1] Ganz offensichtlich treten Memory Leaks in Java so selten auf, dass es eine Herausforderung ist, eines zu erzeugen. Es soll vorgekommen sein, dass Java-Entwickler in Bewerbungsgesprächen gebeten wurden, Memory Leaks zu erzeugen (/ CAM /), um ihre Fähigkeiten unter Beweis zu stellen. |
Was macht der Garbage Collector?
Wie passt die Garbage-Collection-Strategie mit dem Programm zusammen?
Ein Beispiel für ein Memory Leak
Vorbemerkung: Client-Server-Kommunikation
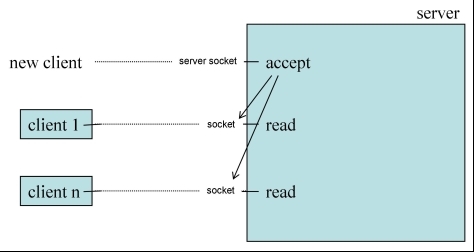
Wenn man Asynchronous Channels verwendet,
geht es im Prinzip genauso. Anstelle des Serversocket benutzt man einen
AsynchronousServerSocketChannel
und statt des Socket einen
AsynchronousSocketChannel
.
Statt die
accept
- und
read
-Aktionen
synchron zu machen, werden sie asynchron abgearbeitet von Callbacks, die
in die Channels eingehängt werden, und vom Framework aufgerufen werden,
sobald Ereignisse/Daten am Channel anliegen.
Der Vorteil der Asynchronous Channels gegenüber
den „normalen“ Sockets ist, dass der Server nicht mit synchronen Methodenaufrufen
der
Socket
-
bzw.
ServerSocket
-Klasse
auf die Aktionen des Clients warten muss. So muss der Server beispielsweise
nicht darauf warten, dass ein Client sich am Serversocket meldet, um akzeptiert
zu werden; er muss auch nicht auf Daten warten, die vom Client gesendet
werden. Die Asynchronous Channels erlauben es, auf diese Ereignisse mit
Callbacks zu reagieren. Dabei nimmt einem der Asynchronous-Channel-Framework
viel Arbeit ab und es ergibt sich trotz Asynchronität ein relativ einfaches
Programmiermodell für den Server. Weitere Details zu den Asynchronous
Channels finden sich in einem unserer zurückliegenden Artikel über die
NIO2 Erweiterungen in Java 7 (/
NIO2
/).
Schauen wir uns nun die Implementierung an.
Den Client-Code werden wir nicht betrachten, weil unser Memory Leak im
Server entsteht. Wir konzentrieren uns deshalb allein auf die Server-Implementierung.
Der gesamte Sourcecode inklusive Test-Clients ist aber unter /
SRC
/
zu finden.
Die Server-Konstruktion
serverSocket Channel = AsynchronousServ erSocketChannel.open();
serverSocket Channel .bind(new InetSocketAddress(SERVER_PORT));
}
Der Konstruktor öffnet den
AsynchronousServerSocketChannel
am
SERVER_PORT
.
Damit steht der Serversocket bereit, mit dem sich der Client verbindet
und an dem der Server Clients akzeptiert.
Accept-Callback einhängen
serverSocketChannel. accept( null, // Zeile 1
new CompletionHandler<AsynchronousSocketChannel,Object>() { /* … later … */ } ); // Zeile 2
}
Die Implementierung des Callbacks (siehe
// Zeile 2) als Anonymous Inner Class schauen wir uns gleich genauer an.
Vorher noch eine Bemerkung zur Semantik der Callbacks bei Asynchronous
Channels: jeder eingehängte Callback bleibt nur so lange aktiv, bis
er aufgerufen wurde. Das heißt, er muss immer wieder neu eingehängt
werden - am Besten gleich als letztes Statement des Callbacks selbst.
Und genau so werden wir es später implementieren (siehe z.B. // Zeile
11).
Der eingehängte Accept-Callback
Für unseren accept - Callback vom Typ CompletionHan dler<AsynchronousSocketChannel, Objekt> (siehe // Zeile 2) müssen zwei Methoden implementiert werden:public void completed(AsynchronousSocketChannel channel, Object attachment) // Zeile 3
public void fail
ed
(Throwable
t, Object attachment)
//
Zeile
4
Die erste Methode
completed()
(siehe // Zeile 3) wird aufgerufen, wenn das Akzeptieren eines Clients
funktioniert. Bei einem erfolgreichen Akzeptieren wird ein neuer Socket
geöffnet, über den anschließend die weitere Kommunikation mit dem Client
geht, der gerade akzeptiert wurde. Bei unserer asynchronen Arbeitsweise
über Callbacks wird der neue Socket vom Typ
AsynchronousSocketChannel
als erster Parameter der
completed()
-Methode
des
accept
-Callbacks zur Verfügung gestellt.
Auf den zweiten Parameter kommen wir gleich noch zu sprechen.
Die zweite Methode
fail
ed
()
(siehe // Zeile 4) wird im Fehlerfall aufgerufen. Ihr erster Parameter
vom Typ
Throwable
beschreibt die genaueren
Umstände des Fehlers. Auf die Fehlerbehandlung wollen wir hier nicht
weiter eingehen. Für unser Problem - das Memory Leak - ist die Fehlerbehandlung
nicht relevant.
Der Vollständigkeit halber sei noch erwähnt,
dass der zweite Parameter beider Methoden (d.h. das
attachment
)
das Objekt ist, das oben als erster Parameter beim Einhängen des Callbacks
mit
accept()
(siehe // Zeile 1) mitgegeben
wurde. Dieses Objekt wird beim Ausführen des Callbacks dann wieder als
zweiter Parameter den Callback-Methoden mitgegeben. Wir haben für dieses
Durchschleusen in unserer Implementierung keine Verwendung, deshalb haben
wir beim
accept()
als ersten Parameter
null
übergeben (siehe // Zeile 1). Das bedeutet, wir können diesen Parameter
im Callback ignorieren.
Die Implementierung des eingehängten Accept-Callback
Kommen wir also nun zur Implementierung der completed() -Methode aus // Zeile 3.public void completed(AsynchronousSocketChannel channel, Object attachment) { // Zeile 5
ClientSession session = new ClientSession(); // Zeile 6
sessionToChannel.put(session, channel); // Zeile 7
final ByteBuffer buf = ByteBuffer.allocateDirect(256); // Zeile 8
channel.read(buf, session, // Zeile 9
new CompletionHandler<Integer, ClientSession>() // Zeile 10
{ /* … later … */ });
serverSocketChannel.accept(null, this); // Zeile 1 1
}
Als erstes erzeugen wir uns ein
ClientSession
-Objekt
für den neuen Client (siehe // Zeile 6). Wie die Klasse
ClientSession
genau aussieht, schauen wir uns gleich weiter unten an. Die Client-Session
ist dafür zuständig, die vom Client empfangenen Daten zu verarbeiten.
Dann merken wir uns in einer Map die Beziehung
zwischen
session
und
channel
(siehe
// Zeile 7). Diese Information brauchen wir später bei der Implementierung
des
read
-Callbacks, der das Empfangen
der Clientdaten behandelt. Die Map
sessionToChannel
ist ein Attribut der
Server
-Klasse, das
so definiert ist:
private final Map<ClientSession, AsynchronousSocketChannel>
sessionToChannel =
new
ConcurrentHashMap<ClientSession, AsynchronousSocketChannel>();
Unsere Map ist vom Type
ConcurrentHashMap,
damit die Callbacks von verschiedenen Clients problemlos konkurrierend
auf sie zugreifen können.
Wie oben bereits erwähnt, wollen wir in
unserem einfachen Beispiel nur Daten vom Client zum Server senden; die
umgekehrte Richtung vom Server zum Client wollen wir nicht implementieren.
Das heißt, was uns nun noch im Server fehlt, ist die Funktionalität für
das Empfangen der Clientdaten (
read
). Das geschieht in // Zeile
8 und // Zeile 9.
Dazu erzeugen wir uns einen
ByteBuffer
,
in den die empfangenen Daten geschrieben werden sollen (siehe // Zeile
8).
Wir hängen diesen
ByteBuffer
zusammen mit der
session
und dem
read
-Callback,
der beim Empfangen der Daten ausgeführt werden soll, in den
channel
zum Client ein; das geschieht über den Aufruf der Methode
read()
(siehe
// Zeile 9). Die Implementierung des
read
-Callbacks
(siehe // Zeile 10) als Anonymous Inner Class schauen wir uns weiter unten
genauer an.
Der zweite Parameter des
read()
,
also die
session
, wird nicht von der
completed()
-Methode
selbst genutzt, sondern durchgeschleust und beim Aufruf des
read
-Callbacks
wieder übergeben. Wie wir weiter unten sehen werden, brauchen wir sie
dort (siehe // Zeile 13 und // Zeile 16). Dieses Durchschleusen eines
Objekts vom Einhängen des Callbacks bis zum Ausführen des Callbacks hatten
wir uns oben bei dem
accept-
Callback
schon
mal angesehen (siehe // Zeile 1), dort aber nicht genutzt, sondern stattdessen
nur
null
übergeben; hier beim
read
-Callback
brauchen wir das Durchschleusen aber.
Wie schon oben erwähnt, bleibt der
accept
-Callback
nur so lange aktiv, bis er aufgerufen wurde. Das heißt, er muss immer
wieder neu eingehängt werden, damit weiterhin neue Clients akzeptiert
werden. Dieses Wiedereinhängen machen wir als letzte Aktion in der
completed()
-Methode
(siehe // Zeile 11). Wir nehmen einfach den Callback wieder, der gerade
ausgeführt wird. Das heißt der zweite Parameter im erneuten
accept()
-Aufruf
ist
this
und der erste ist
null
wie schon oben in // Zeile 1, weil wir kein Objekt an den
accept
-Callback
durchschleusen wollen.
Die Client-Session
class ClientSession {
private static final AtomicInteger clientCnt = new AtomicInteger(1);
private final int myId = clientCnt.getAndIncrement();
private volatile int byteCnt;
public boolean handleInput(ByteBuffer buf, int len) { // Zeile 1 2
if (len >= 0) {
byteCnt += len;
return true;
} else {
System.out.println("received " + byteCnt + " bytes from client " + myId);
return false;
}
}
}
In unserem einfachen Server-Beispiel simuliert
diese Klasse eigentlich nur die Funktionalität, die typischerweise in
einer Client-Session angesiedelt ist. Zum Beispiel kann man sich vorstellen,
dass in einem echten Server, bei dem die Kommunikation aus XML-Dokumenten
besteht, die empfangenen Daten in der Session gespeichert werden, bis sie
ein vollständiges Dokument ergeben, das geparst und weiterverarbeitet
werden kann.
Die zentrale (und einzige) Methode unserer
Client-Session ist die
handleInput()
-Methode
(beginnend in // Zeile 12). In unserem einfachen Fall wird in der
handleInput()
-Methode
nur die Anzahl der vom Client empfangenen Bytes gezählt, solange bis der
Client die Verbindung beendet. Dann wird die Anzahl zusammen mit der
Client-Session-ID ausgedruckt. Der Returnwert der
handleInput()
-Methode
ist
true
, wenn weiterer Input erwartet
wird, und
false
, wenn die Verbindung
beendet ist. Die Methode
handleInput()
arbeitet sehr eng mit dem
read
-Callback
zusammen, der das Empfangen der Daten abhandelt.
Der eingehängte Read-Callback
AsynchronousSocketChannel channel = sessionToChannel.get( session); // Zeile 13
if ( session.handleInput(buf, len)) { // Zeile 14
buf.clear(); // Zeile 15
channel.read(buf, session, this); // Zeile 16
}
else {
try { channel.close(); } // Zeile 17
catch (IOException e) { /* ignore */ }
}
}
Die Parameter der Methode sind
len
,
die Anzahl der Bytes, die vom Client empfangen wurden, und die
ClientSession
,
die hierhin vom
read(
)
-Aufruf
(in // Zeile 9) durchgeschleust wurde. Wir holen uns als erstes den zur
session
korrespondierenden
channel
aus unserer
sessionToChannel
-Map
(siehe // Zeile 13).
Dann rufen wir auf der session die handleInput() -Method auf und übergeben dabei den ByteBuffer buf mit den Inputdaten sowie die Anzahl der Bytes, die in den ByteBuffer gelesen wurden (siehe // Zeile 14). Wir haben Zugriff auf den Puffer buf , weil er im äußeren Scope (dem der completed( ) -Methode des accept - Callbacks) final deklariert war (siehe // Zeile 8) und wir in der inneren Klasse (der Implementierung des des read- Callbacks) Zugriff auf die final Variablen des äußeren Scopes haben.
Der Code des
if
-
und
else
-Zweigs ist relativ übersichtlich.
Im Fall von „Weiterlesen“ (
if
-Zweig) setzten
wir den ByteBuffer mit
clear()
zurück
(siehe // Zeile 14), um ihn anschließend im
rea
d-
Callback
wieder zu verwenden (siehe // Zeile 16). Wie oben im
ac
cept-
Callback
setzeen wir wieder den Callback, den wir gerade durchlaufen, als Callback
in den
channel
ein. Der dritte Parameter
von
read()
ist deshalb
this
.
Im Fall von „Verbindung beenden“ (
else
-Zweig)
rufen wir die
close()
Methode auf dem
channel
auf (siehe // Zeile 17). Wir müssen dies in einem
try
-Block
tun, da
close()
eine
IOException
werfen kann. Eine Behandlung der Exception implementieren wir nicht.
Was soll man auch tun, wenn ein
close()
nicht fehlerfrei funktioniert? Wiederholen? Wie häufig?
Ohnehin, an der fehlenden Behandlung der IOException hier liegt das Memory Leak nicht. Auf das Memory Leak können wir nämlich jetzt zurückkommen. Wir haben uns nun den gesamten Code des Servers angesehen. Wo haben wir Objekte vergessen, die den Speicherverbrauch kontinuierlich anwachsen lassen?
Wo ist das Memory Leak?
Korrektur: Eliminierung des Memory Leaks
Lösung #1:
AsynchronousSocketChannel channel = sessionToChannel.get( s ession);
if (session.handleInput(buf, len)) {
buf.clear();
channel.read(buf, session, this);
}
else {
sessionToChannel.remove(session);
try { channel.close(); }
catch (IOException e) { /* ignore */ }
}
}
Diese Korrektur ist zwar naheliegend, aber nicht unbedingt die im Gesamtkontext schlüssigste. Sinnvoll wäre eine Lösung, bei der man den Map-Eintrag und damit die Map nicht braucht, so dass man das Löschen des Map-Eintrags gar nicht erst vergessen kann.
Lösung #2:
public void completed( final AsynchronousSocketChannel channel, Object attachment) { // Zeile 5
...
}
Da der read - Callback als Anonymous Inner Class im Scope dieser Methode implementiert ist, kann er so direkt auf den channel zugreifen und braucht ihn sich nicht aus der Map zu holen. Diese Lösung wollen wir an dieser Stelle nicht in allen Details zeigen. Sie ist im Sourcecode unter /SRC/ zu finden.
Lösung #3:
Fazit
Zusammenfassung und Ausblick
Verweise
| /ARGC/ |
Klaus
Kreft, Angelika Langer: Artikelserie zur Garbage Collection
URL:
http://www.AngelikaLanger.com/Articles/EffectiveJava.html
|
|
Creating
a memory leak with Java
URL:
http://stackoverflow.com/questions/6470651/creating-a-memory-leak-with-java
|
|
|
Garbage Collection Teil 2: Young Generation Garbage Collection
Klaus Kreft, Angelika Langer, Java Magazin, April 2010 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/50.GC.YoungGenGC/50.GC.YoungGenGC.html |
|
|
Garbage Collection Teil 3: Old Generation Garbage Collection - Mark
And Compact
Klaus Kreft, Angelika Langer, Java Magazin, Juni 2010 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/51.GC.OldGen.MarkCompact/51.GC.OldGen.MarkCompact.html |
|
|
Garbage Collection Teil 4: Old Generation Garbage Collection - CMS
Klaus Kreft, Angelika Langer, Java Magazin, August 2010 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/52.GC.OldGen.CMS/52.GC.OldGen.CMS.html |
|
|
Garbage Collection Teil 8: "Garbage First" (G1) Garbage Collector
Klaus Kreft, Angelika Langer, Java Magazin, April 2011 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/56.GC.G1.Details/56.GC.G1.Details.html |
|
|
Java Core Programmierung: Memory Model und Garbage Collection
Klaus Kreft, Angelika Langer, entwickler.press, August 2011 ISBN: 978-3-86802-075-5, E-Book-ISBN: 978-3-86802-262-9 |
|
|
Java 7 Teil 4: NIO2 - File System API & Asynchronous I/O
Klaus Kreft, Angelika Langer, Java Magazin, Dezember 2011 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/60.Java7.NIO2/60.Java7.NIO2.html |
|
|
Sourcecode
für das Memory-Leak-Beispiel aus diesem Artikel
URL:
http://www.AngelikaLanger.com/Articles/EffectiveJava/66.Mem.Analysis/66.Mem.Analysis.zip
|
Die gesamte Serie über Memory Leaks:
| /MEMLKS-1/ |
Memory Leaks - Ein Beispiel
Klaus Kreft & Angelika Langer, Java Magazin, August 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/64.Mem.Leaks/64.Mem.Leaks.html |
| /MEMLKS-2/ |
Akkumulation von Memory Leaks
Klaus Kreft & Angelika Langer, Java Magazin, Oktober 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/65.Mem.Akkumulation/65.Mem.Akkumulation.html |
| /MEMLKS-3/ |
Memory Leaks - Referenzen "ausnullen"
Klaus Kreft & Angelika Langer, Java Magazin, Dezember 2012 URL: http://www.angelikalanger.com/Articles/EffectiveJava/66.Mem.NullOut/66.Mem.NullOut.html |
| /MEMLKS-4/ |
Tools für die dynamisch Memory Leak Analyse
Klaus Kreft & Angelika Langer, Java Magazin, Februar 2013 URL: http://www.angelikalanger.com/Articles/EffectiveJava/67.MemLeak.ToolCyclic/67.MemLeak.ToolCyclic.html |
| /MEMLKS-5/ |
Heap Dump Analyse
Klaus Kreft & Angelika Langer, Java Magazin, April 2013 URL: http://www.angelikalanger.com/Articles/EffectiveJava/68.MemLeak.ToolDump/68.MemLeak.ToolDump.html |
| /MEMLKS-6/ |
Weak References
Klaus Kreft & Angelika Langer, Java Magazin, Juni 2013 URL: http://www.angelikalanger.com/Articles/EffectiveJava/69.MemLeak.WeakRefs/69.MemLeak.WeakRefs.html |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||||
Seminar
|
||||