| Angelika Langer - Training & Consulting |
| HOME | |

|
|

|
|

OVERVIEW
BY COLUMN
BY MAGAZINE
|
|
| GENERICS | |
| LAMBDAS | |
| IOSTREAMS | |
| ABOUT | |
| CONTACT |
|
Java Multithread Support
Multithread Grundlagen
JavaSPEKTRUM, Januar 2004
|
Dies ist das Manuskript eines Artikels, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im JavaSPEKTRUM erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar ( click here ). |
In vorhergehenden Artikeln haben wir uns einige Methoden angesehen, die von der gemeinsamen Basisklasse Object zur Verfügung gestellt werden. Wir haben diskutiert, wie diese Methoden in abgeleiteten Klassen zu nutzen bzw. zu überschreiben sind. Die betreffenden Methoden waren: clone() , equals() und hashcode() . Neben den genannten Methoden beschreibt die JavaDoc von Object noch acht weitere Methoden, von denen allein fünf dem Themenkomplex „Multithread-Support in Java“ zugerechnet werden können: wait() (in drei überladenen Versionen ) sowie notify() und notifyAll() .
Ähnlich wie bei clone() , equals() und hashcode() ist es schwierig, wenn nicht unmöglich, die korrekte Nutzung dieser Methoden allein durch das Lesen der JavaDoc-Beschreibungen zu verstehen, insbesondere weil in den Beschreibungen Begriffe aus der Multithread-Programmierung bereits vorausgesetzt werden. Der erste Satz zu notifyAll() lautet zum Beispiel: “Wakes up all threads that are waiting on this object's monitor (/ JDOC /).” Hier muss der Leser der JavaDoc schon etwas mehr Kenntnisse mitbringen, als nur die Erkenntnis, dass mit „Monitor“ offensichtlich nicht der Bildschirm des Rechners gemeint ist.
Wir werden in diesem und den folgenden Artikeln die Details der Multithread-Programmierung
in Java diskutieren. Obwohl der Multithread-Support in Java schon seit
den Anfangstagen der Sprache in relativ unveränderter Form existiert,
gibt es einen aktuellen Anlass für das Thema. Mit dem JDK 1.5 (der
Mitte des Jahres freigegeben werden soll) wird es hier die ersten großen
Ergänzungen geben, die wohl auch zu Änderungen bei Multithread-Programmieridiomen
führen werden. Zu den Neuerungen gehören einerseits die neuen
Concurrency Utilities, die eine ganze Reihe von nützlichen High-Level-Abstraktionen
für die Multithread-Programmierung liefern werden, aber auch die Änderungen
am Java Memory Model, die u.a. Klärungen und Änderungen im Bereich
der unsynchronisierten Zugriffe auf
volatile
und
final
Variablen bringen werden. (Dem interessierten Leser seien in diesem
Zusammenhang die Spezifikationen der entsprechenden Java Community Groups
JSR 133 für das Java Memory Model (siehe /
JSR133
/)
und JSR 166 für die Concurrency Utilities (siehe /
JSR166
/)
empfohlen.) Selbstverständlich werden wir diese Ergänzungen und
ihre Auswirkungen in diesem Artikel bereits berücksichtigen und in
späteren Artikeln dieser Kolumne genauer beschreiben.
Eine kurze Geschichte der Systemarchitektur
Um den Multithread-Support in Java diskutieren zu können, ist es erst einmal wichtig zu verstehen, was Threads allgemein sind und wie sie sich von verwandten Systemabstraktionen wie Prozessen unterscheiden.In den Anfängen der IT-Welt gab es keine Threads, ja nicht einmal Prozesse. Auf einem Rechner gab es nur eine einzige Ausführungseinheit. Das war entweder das Betriebssystem, das direkt die Ein-/Ausgabe bediente, oder das Betriebssystem führte ein Anwendungsprogramm aus, welches dann die Kontrolle über die Ein-/Ausgabe übernahm. Diese eine Ausführungseinheit hatte dabei sowohl als Betriebssystem als auch als Anwendungsprogramm die volle Kontrolle über CPU und Speicher. (Ein gutes Beispiel für eine solche Konstellation ist ein PC mit dem Betriebssystem MS-DOS. Zwar stammt MS-DOS nicht einmal aus den Anfängen der Informationstechnologie, aber es hat in gewissem Sinne die Entwicklung der Großrechnerwelt auf dem PC wiederholt.)
Über verschiedene Entwicklungsstufen entstand die Systemarchitektur, wie wir sie vom UNIX der späten 80er / frühen 90er Jahre her kennen. Ein Rechner hat mehrere Ausführungseinheiten, die Prozesse genannt werden. Diese teilen sich die Rechnerleistung der CPU (oder der CPUen) des Rechners. Dabei wird die CPU-Leistung nach Algorithmen verteilt, die im Betriebssystem implementiert sind. Jeder Prozess hat seinen eigenen Stack und auch die Heapdaten sind im eigenen Adressraum vor dem Zugriff anderer Prozesse geschützt. Die Ausführung eines Anwendungsprogramms läuft in einem Prozess oder über mehrere Prozessen verteilt ab. So ist sichergestellt, dass sich verschiedene Anwendungen nicht gegenseitig blockieren oder behindern. Die Adressraumgrenzen sorgen dafür, dass Daten nicht gegenseitig überschrieben werden. Das Prozess-Scheduling des Betriebssystem sorgt dafür, dass die Rechnerleistung fair auf alle Prozesse verteilt wird. Kleinere Nachteile hat diese Architektur dann, wenn eine Anwendung aus mehreren Prozesse besteht: um Daten zwischen den einzelnen Prozessen auszutauschen, muss auf sogenannte IPC-Mechnismen (IPC = Inter Process Communication) zurückgegriffen werden. Komunikation über IPC-Mechanismen ist langsamer und ressourcenintensiver als direkte Speicherzugriffe. Außerdem ist sie aufwändiger zu programmieren als direkte Speicherzugriffe.
An dieser Stelle kommen nun Threads ins Spiel. Threads sind parallele Ausführungseinheiten innerhalb einer Anwendung, die direkt über Speicherzugriffe miteinander kommunizieren können, ohne aufwändige IPC-Mechanismen nutzen zu müssen. Innerhalb eines Prozesses hat man nun mehrere Threads, die alle im selben Adressraum ablaufen, aber ihren eigenen Stack haben. Jeder Thread bildet dabei eine eigene Ausführungseinheit, so dass es relativ natürlich ist, die parallelen Funktionen eines Anwendungsprogramms den Threads eines Prozesses zu zuordnen. Da alle Threads eines Prozesses auf dieselben Heapdaten zugreifen können, können sie Daten untereinander schnell und effizient austauschen.. Das Scheduling des Betriebssystem sorgt dafür, dass die Rechnerleistung fair auf Prozesse und ihre Threads verteilt wird. (Beispiele für diese Architektur sind alle Microsoft Betriebssysteme seit Windows NT und neuere UNIX Derivate inklusive Linux.)
In den Programmiersprachen, die zur Zeit der Einführung von Threads populär waren (dies waren im wesentlichen C und C++), wurde die Multithread-Funktionalität über neue Bibliotheks-APIs zugänglich gemacht. Ein Beispiel für ein solches API ist IEEE POSIX 1003.1c (/ PTH /), auch bekannt als POSIX Threads oder Pthreads. Ein Nachteil dieses Bibliotheksansatzes ist ganz offensichtlich: eine Anwendung, die in C bzw. C++ implementiert ist und Multithreading nutzt, ist niemals portabel, sondern immer an ein bestimmtes Multithread-API gebunden.
Da Java erst nach der Einführung von Threads entstanden ist, wurde
getreu nach dem Java-Motto „Write once, run everywhere.“ der Multithread-Support
plattformübergreifend direkt in die Sprache integriert. Die Java Language
Specification (/
JLS
/) beschreibt alle Details des Verhalten
von Threads, die für eine Java-Implementierung, die Multithreading
nutzt, relevant sind.
Ein erstes Multithread-Beispiel
Kommen wir nun zu den Details der Multithread-Programmierung in Java. Im vorhergehenden Abschnitt haben wir bereits erwähnt, dass verschiedene Threads Daten auf dem Heap gemeinsam lesen und verändern können. Verglichen mit IPC-Programmierung ist das sehr einfach zu programmieren. Trotzdem gibt es nun neue Regeln, die zu beachten sind, wenn verschiedene Threads auf dieselben Daten zugreifen.Dazu schauen wir uns ein Beispiel an:
public class IntStack {Der Code zeigt einen Ausschnitt aus der Implementierung einer Klasse IntStack , die es erlaubt, int -Werte in einer Stack-artigen Struktur zu speichern. Jedes IntStack -Objekt kann eine maximale Anzahl von int -Werten speichern; diese Anzahl wird im Konstruktor festgelegt. Wie bei einem Stack üblich, fügt die Methode push() einen int -Werte am Ende der Sequenz ein. Falls der Stack bereits voll ist, wird eine IndexOutOfBoundsException geworfen, welche eine Runtime-Exception ist.
private final int[] array;
private int cnt = 0;public IntStack (int sz) { array = new int[sz]; }
public void push (int elm) {
if (cnt < array.length) {
array[cnt] = elm;
cnt++;
}
else throw new IndexOutOfBoundsException();
}// und weitere Methoden wie pop(), ...
}
Nehmen wir nun an, wir haben eine Java-Anwendung, in der zwei verschiedene Threads Zugriff auf eine Instanz des IntStack s haben, und beide Threads rufen die push() -Methode auf (siehe Abbildung 1). Beiden Threads wird ihre Laufzeit vom Threadscheduler zugewiesen. Dabei ist es grundsätzlich möglich, dass die Ablaufreihenfolge so ist, dass der erste Thread vom Scheduler unterbrochen wird, nachdem er das Statement array[cnt] = elm; der push() -Methode aufgerufen hat, und nun der zweite Thread laufen darf. Nachdem der zweite Thread die push() Methode vollständig ausgeführt hat, gibt es wieder einen Wechsel zum ersten Thread, der nun den Rest der push() -Methode ausführt. Ein solches Szenario ist in Abbildung 2 dargestellt. Natürlich ist eine solche Abfolge nicht zwingend, aber sie ist möglich.
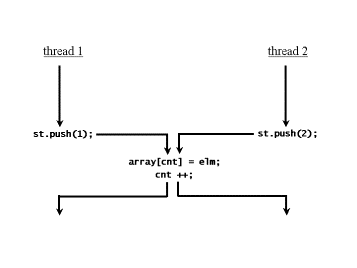
Abbildung 1: Zwei Threads mit Zugriff auf ein gemeinsam verwendetes IntStack-Objekt
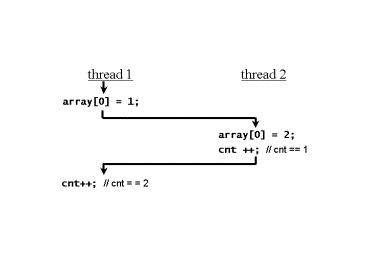
Abbildung 2: Verschränkter Ablauf der push()-Methode
Was ist bei einem solchen Ablauf mit dem Stack geschehen?
Das heißt, unter dem Strich haben wir nicht die Werte im Stack, die wir hineingetan haben, und wir bekommen beim ersten Herausnehmen keinen sinnvollen int -Wert, sondern einen ziemlich zufälligen, der vermutlich von einer vorherigen Nutzung oder Initialisierung des IntStack -Objekts stammen wird.Der erste an der Stelle array[0] durch den ersten Thread eingetragene Wert ist sofort durch den zweiten Thread überschrieben worden, weil das cnt++ des ersten Threads wegen des Threadwechsels nicht ausgeführt werden konnte. Das spätere Ausführen des cnt++ durch den ersten Thread führt dazu, dass der Stackpointer noch einmal verändert wird, obwohl sich an der Stelle array[1] gar kein zulässig eingetragener Wert befindet.
Grundlagen der Multithread-Programmierung
Wie wir schon kurz angedeutet haben ist die Ursache für diesen Fehler in der verschränkten Ausführung der push() -Methode zu sehen: das cnt++ des ersten Threads konnte nicht vor dem Threadwechsel ausgeführt werden, statt dessen konnte der zweite Thread die push() -Methode des Stack-Objektes ausführen. Bevor wir uns im Detail ansehen, was Java zur Lösung dieses Problems anbietet, wollen wir diskutieren, was allgemein hinter diesem Problem steckt und welche Möglichkeiten es gibt, um solche Probleme frühzeitig zu erkennen. Um eine Diskussionsgrundlage für eine solche Betrachtung zu haben, vervollständigen wir zunächst einmal unsere IntStack -Implementierung:public class IntStack {
private final int[] array;
private int cnt = 0;public IntStack (int sz) { array = new int[sz]; }
public void push (int elm) {
if (cnt < array.length) array[cnt++] = elm;
else throw new IndexOutOfBoundsException();
}public int pop () {
if (cnt > 0) return(array[--cnt]);
else throw new IndexOutOfBoundsException();
}public int peek() {
if (cnt > 0) return(array[cnt-1]);
else throw new IndexOutOfBoundsException();
}public int size() { return cnt; }
public int capacity() { return (array.length); }
}
Atomare Operationen
Beginnen wir unsere Diskussion mit der nun leicht veränderten Version der push() -Methode. Um den Sourcecode der gesamten Klasse etwas kompakter aufzuschreiben, haben wir die beiden Aktionen:- Eintragen des int -Wertes in das Array und
- Verändern des Stackpointers cnt
Damit ergibt sich die Frage: Hätte uns diese kleine Veränderung vor einem Ablauf, wie weiter oben diskutiert, bewahrt? Mit anderen Worten: würde auf diese Weise kein Threadwechsel zwischen Eintragen des Wertes ins Array und Verändern des Stackpointers auftreten, da beide Aktionen jetzt in einem Statement sind?
Die kurze Antwort ist: Nein. Die ausführlichere Antwort lautet: Statementgrenzen haben keinerlei Einfluss auf das Threadscheduling.
Es gibt aber Operationen, die Einfluss auf das Threadscheduling haben, d.h. Operationen, die nicht vom Scheduler unterbrochen werden und damit garantiert vollständig ausgeführt werden. Solche Operationen werden als atomar bezeichnet. Laut Java Language Specification sind die atomaren Operationen (a) die Lese- und Schreiboperationen für alle primitiven Datentypen außer double und long , sowie (b) das Lesen und Schreiben von Objektreferenzen. Die atomaren Operationen in Java sind damit deutlich feingranularer als ein Statement. Dass sie uns trotzdem weiterhelfen, werden wir zu einem späteren Zeitpunkt noch sehen.
Was die 64-bit Datentypen double und long angeht, so ermutigt die Java Language Specification die Anbieter von Virtuellen Maschinen sie so zu implementieren, dass auch für diese Datentypen Lese- und Schreiboperationen atomar sind. Trotzdem wird man als Java Nutzer aus Gründen der Portabilität den eigenen Code immer so implementieren, als wären sie nicht atomar.
Das abstrakte Problem
Im folgenden werden wir uns die Ausgangssituation noch einmal an unserem Beispiel ansehen und versuchen, allgemeine Gründe zu finden, warum wir Probleme bekommen haben. Wir haben bereits festgestellt, dass in unserem Szenario der Threadwechsel zwischen dem Eintragen des int -Wertes ins Array und dem Verändern des Stackpointers cnt die Ursache des Problems ist. Abstrakt betrachtet bedeutet dies, dass unser Stack-Objekt in einem inkonsistenten Zustand war, als der Threadwechsel auftrat: die beiden Attribute des Objekts array und cnt passten nicht zu einander. Dies ist aber erst einmal nur ein potentielles Problem. Wirklich schief gegangen ist es dann dadurch, dass im zweiten Thread auf das inkonsistente Stack-Objekt zugegriffen wurde und zwar mit der push() -Methode, die zum fehlerfreien Ablauf aber ein konsistentes Objekt voraussetzt.Das sind dann auch schon die beiden Aspekte, auf die man eine Methode im Multithread-Umfeld untersucht:
- Verändert sie Attribute, so dass diese während des Ablaufs der Methode irgendwann zueinander inkonsistent werden?
- Welche Attribute müssen konsistent sein, damit die Methode korrekt ausgeführt werden kann?
Konfliktmenge
Neben der Analyse der einzelnen Methoden ist die Untersuchung der Kombination von Methoden wichtig: was kann geschehen, wenn die eine Methode in einem Thread ausgeführt wird, während die andere zur gleichen Zeit in einem anderen Thread läuft? Dabei gehen die Vorüberlegungen aus der Analyse der einzelnen Methoden ein: welche Konsistenz verletzt die eine Methode und welche Konsistenz setzt die andere Methode voraus (und umgekehrt)? Kann es dabei zu Fehlern kommen?
Wenn man mit solchen Überlegungen noch nicht so vertraut ist, kann
man das ganze relativ formal angehen, indem man sich die Kombination aller
Methoden einer Klasse ansieht. Zur Verdeutlichung wollen wir hier das Beispiel
mit den Methoden des IntStacks betrachten. Die Tabelle aller relevanten
Kombinationen von Methoden miteinander bildet eine Dreiecksmatix, weil
das Problem symmetrisch ist: wenn
push()
mit
pop()
verträglich oder unverträglich ist, dann gilt das gleiche auch
für die umgekehrte Kombination
pop()
und
push()
.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|||
|
|
|
Wir werden jetzt die einzelnen Kombinationen untersuchen und solche Kombinationen aus der Tabelle löschen, die ohne Probleme parallel ablaufen können. Was uns dann bleibt, ist die Menge an Kombinationen, bei denen es potenziell zu Konflikten kommen kann.
push/push
Wie wir bereits gesehen haben, kann es hier zu Konflikten kommen: Beide Methoden verändern Array-Inhalt und Stackpointer. Also lassen wir die Kombination in der Tabelle.push/pop
pop() verändert zwar nur den Stackpointer und nicht das Array; auf das Array wird nur lesend zugegriffen. Aber, um richtig ablaufen zu können, verlangt pop() die Konsistenz von Array-Inhalt und Stackpointer. Daher ist die Kombination mit einer schreibenden Methode wie push() potenziell problematisch und die Kombination push/pop bleibt in der Tabelle.pop/pop
Wie ist es bei dieser Kombination? Da pop() nur den Stackpointer verändert, können eigentlich keine Attribute untereinander inkonsistent werden. Hinzu kommt, dass der Stackpointer cnt vom Type int ist und damit garantiert ist, dass die Lese- und Schreiboperationen beim cnt-- atomar sind. Der andere Thread sieht entweder den alten oder den neuen Wert des Stackpointers. Trotzdem kann es Probleme geben. Was ist, wenn der zweite Thread noch den alten Wert des Stackpointers sieht? Dann wird zweimal der erste Wert vom Stack geholt, während der zweite Wert ganz verloren geht.Man sieht also, dass die Konsistenz eines Objekt nicht nur auf Grund der Inhalte der Attribut untereinander zu bewerten ist, sondern auch bezüglich der Semantik des Objekts: wenn der Stackpointer noch nicht dekrementiert wurde, der Wert aber schon aus dem Array gelesen worden ist, so ist dies ebenfalls eine Inkonsistenz zur Semantik eines Stacks. Die Kombination pop/pop bleibt also in der Tabelle.
push/peek, pop/peek
peek() ist nur eine lesende Methode, d.h. sie verändert weder den Inhalt des Arrrays noch den Stackpointer. Sie produziert keine Inkonsistenzen, mit denen push() oder pop() leben müssten. Umgekehrt ist es aber so, dass push() und pop() den Stackpointer verändern. Wenn diese Stackpointerveränderung nicht konsistent zur Semantik des Stacks erfolgt (siehe Diskussion unter pop/po p), gibt peek() nicht das richtige (d.h. das oberste) Element des Stacks zurück. Beide Kombinationen bleiben also in der Tabelle.peek/peek
Da, wie bereits gesagt, peek() nur eine lesende Methode ist, können bei der Kombination von zwei lesenden Methoden keine Inkonsistenzen auftreten, da gar keine Veränderungen auftreten. Das heißt diese Kombination fällt aus der Tabelle heraus, weil sie unproblematisch ist.push/size, pop/size
size() ist genau wie peek() eine nur lesende Methode. Genauso wie bei peek() wird der Stackpointer genutzt, der von push() und pop() verändert wird. Trotzdem wollen wir die beiden Kombinationen nicht in der Tabelle lassen, weil die Methode size() nicht von anderen Methode in einem anderen Thread unterbrochen werden kann.Die Methode size() macht nichts weiter, als auf den Stackpointer cnt zuzugreifen und ihn als Returnwert zurückzugeben. Das ist eine Aktion, die nicht unterbrochen werden kann, weil die Java Language Specification garantiert, dass der Zugriff auf Objekte von primitivem Typ (außer long und double ) atomar ist. Eine ganz andere Situation würde sich ergeben, wenn unser Stackpointer cnt vom Typ long wäre. Das wäre denkbar, wenn unser Stack-Objekt extrem groß werden kann. In dem Fall ist nicht sichergestellt, dass der Lesezugriff auf den Stackpointer atomar ist. Es könnte passieren, dass wir als Ergebnis der Methode einen Mix der Bits des alten und des neuen Wertes bekämen, der ein völlig falscher Wert für die Größe des Stacks wäre. Das heißt, wenn der Stackpointer cnt vom Typ long wäre, würden wir diese Kombinationen mit push() und pop() in der Tabelle lassen.
Wenn nun zwei Threads gleichzeitig push() (oder pop() ) und size() ausführen, dann kann zwar ein push() oder pop() die Methode size() nicht unterbrechen, aber es könnte umgekehrt die size() Methode mitten im Ablauf von push() oder pop() ausgeführt werden. push() und pop() ändern den Stackpointer cnt und es könnte passieren, dass size() den bereits modifizierten Wert cnt zurückliefert, obwohl die push() oder pop() Methode noch gar nicht fertig ist. Ist das ein Problem?
Nein, das sieht zwar auf den ersten Blick aus wie Problem, ist aber keines. Der mögliche Fehler bei einer Kombination mit size() ist ja nur, dass die gelieferte Stackgröße nicht dem wirklich aktuellen Wert entspricht, sondern (bei Kombination mit push() ) um eins kleiner oder (bei Kombination mit pop() ) um eins größer ist. Das klingt jetzt erst einmal dramatisch; manche Programme sind schon abgestürzt, „nur“ weil ein Schleifenzähler um eins zu groß oder zu klein war. Aber schauen wir uns die Situation noch einmal an: Genau die gleiche Stackgröße bekommen wir ja auch, wenn die push() oder pop() Methode noch gar angefangen hat, ehe die size() Methode den Wert des Stackpointers liest. Da wir aber, wenn wir zwei Threads haben, nie ganz genau sagen können, wann size() auf push() oder pop() trifft, müssen wir sowieso mit dieser Situation leben. Das Programm ist ohnehin darauf vorbereitet, dass es eine „zufällige“ (vor oder nach push() oder pop() ermittelte) Stackgröße geliefert bekommt.
peek/size, size/size
Dies ist einfach: Die Methoden beider Kombinationen greifen nur lesend auf die Attribute zu. Damit kann nichts schief gehen und wir entfernen die beiden Kombinationen aus der Tabelle.*/capacity
capacity() greift lesend auf array.length zu, d.h. es ist eine rein lesende Methode und array ist final , d.h. array verweist immer auf das gleiche bei der Konstruktion zugewiesene int -Array. Da ein int[] in Java seine Größe nicht verändern kann, ist array.length eine Konstante für die gesamte Lebenszeit des Stack-Objekts. Aus diesem Grund kann keine andere Methode in Konflikt mit capacity() kommen. Deshalb entfernen wir alle Kombinationen mit capacity() aus der Tabelle.
Unter Umständen stellt man sich die Frage, ob auch der Konstruktor
bei der Ermittlung der Konfliktmenge zu berücksichtigen ist. Dem ist
aber im allgemeinen nicht so. Die Begründung dafür ist: Zu dem
Zeitpunkt, wenn der Konstruktor ausgeführt wird, gibt es noch keine
Referenz auf das Objekt. Die Referenz auf das neu konstruierte Objekt wird
ja erst als Ergebnis des
new
-Statements zurückgeliefert,
also wenn die Ausführung des Konstruktors bereits beendet ist. Erst
dann können die anderen Methoden auf dem Objekt aufgerufen werden.
Es gibt allerdings dennoch eine Situation, in der diese Argumentation
nicht richtig ist, nämlich im Falle von Selbstregistrierung. Bei einer
solchen Registrierung übergibt ein Objekt die eigene Selbstreferenz
this im Konstruktor an ein anderes Objekt. Vom Registrierungszeitpunkt
an kann diese Referenz dann auch von einem anderen Thread genutzt werden.
In einem solchen Fall ist eine gewisse Vorsicht angebracht. Diese problematische
Situation kann man vermeiden, wenn das Registrierungsstatement ans Ende
des Konstruktors verschoben wird, aber das hilft nur, wenn die Klasse keine
Subklassen hat. Einige zusätzliche Details zu dieser Situation finden
sich in einem unserer vorhergehenden Artikel /
KRE
/,
in dem wir diskutiert haben, dass Selbstregistrierung auch ohne Berücksichtigung
von mehreren Threads bereits problematisch sein kann.
Zusammenfassend lässt sich sagen, dass wir im Fall des
IntStack
den Konstruktor nicht berücksichtigen müssen, da keine Selbstregistrierung
im Konstruktor vorgenommen wird.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|||
|
|
|
Die Java Lösung: synchronized
Was kann man nun in Java tun, um die potentiellen Konflikte zwischen zwei Methoden zu eliminieren? Java gibt dem Entwickler die Möglichkeit, Methoden (mit Ausnahme von Konstruktoren) mit dem Keyword synchronized zu versehen. Alle Methoden eines Objekts, die synchronized sind, können nicht durch andere Methoden desselben Objekts, die ebenfalls synchronized sind, unterbrochen werden. Oder anders ausgedrückt: synchronized Methoden eines Objekts verhalten sich untereinander atomar. Ihre Ausführung wir immer sequenzialisiert; erst wird die eine Methode zu Ende ausgeführt, bevor die andere gestartet wird. Wenn wir push() synchronized deklarieren, eliminieren wir damit den potentiellen Konflikt, der in der Kombination von push/push steckt. Denn nun kann es nicht mehr vorkommen, dass push() nach dem Eintragen des Wertes in das Array, aber vor dem Verändern des Stackpointers, durch einen weiteren Aufruf von push() auf demselben Objekt unterbrochen wird. Um die andern Konflikte unserer Tabelle aufzulösen, müssen wir zusätzlich noch pop() und peek() synchronized deklarieren. Eine Implementierung des IntStack , die problemlos in einer Multithread-Umgebung genutzt werden kann, wird als threadsicher (englisch: thread-safe) bezeichnet. Sie sieht folgendermaßen aus:public class IntStack {Eine solche Implementierung führt dazu, dass konkurrierende peek() -Zugriffe auf ein IntStack -Objekt ebenfalls sequenzialisiert werden. Damit sinkt unnötigerweise die Parallelität und damit auch die Performance eines Programms, das den IntStack nutzt. Ein Blick auf unsere Konfliktmenge zeigt uns, dass es bei dieser Kombination gar kein potentielles Problem gibt. Die Schwierigkeit bei einer optimalen Serialisierung ist, dass peek() zwar gegen schreibende Methoden wie push() und pop() geschützt werden muss, nicht aber gegen andere nur lesende Methoden wie peek() . Es gibt bis heute in Java keine einfache, direkte Möglichkeit, um dieses Problem zu lösen. Es wird aber mit JDK 1.5 an dieser Stelle neue Möglichkeiten geben. Wie bereits gesagt, mehr dazu in einem zukünftigen Artikel, der sich mit den im JDK 1.5 neuen Multithread-Features beschäftigen wird.
private final int[] array;
private volatile int cnt = 0;public IntStack (int sz) { array = new int[sz]; }
synchronized public void push (int elm) {
if (cnt < array.length) array[cnt++] = elm;
else throw new IndexOutOfBoundsException();
}synchronized public int pop () {
if (cnt > 0) return(array[--cnt]);
else throw new IndexOutOfBoundsException();
}synchronized public int peek() {
if (cnt > 0) return(array[cnt-1]);
else throw new IndexOutOfBoundsException();
}public int size() { return cnt; }
public int capacity() { return (array.length); }
}
Verwendung von volatile
Wir haben in der oben gezeigten threadsicheren Implementierung des IntStack neben der Deklaration der Methoden push() , pop() und peek() als synchronized –Methoden noch eine weiteren Änderung vorgekommen: wir haben den Stackpointer cnt als volatile deklariert. Das ist nötig, damit andere Threads beim Zugriff auf diese Instanzvariable den jeweils aktuellen Wert des Stackpointers sehen können. Wenn cnt nicht als volatile erklärt ist, dann gibt es keine Garantie, dass Änderungen dieser Variable, die in einem Thread gemacht wurden, in anderen Threads sichtbar sind, wenn diese anderen Threads auf die Variable zugreifen. Auf die Details wollen wir an dieser Stelle nicht eingehen. Im allgemeinen ist anzuraten, veränderliche Instanzvariablen immer dann als volatile zu deklarieren, wenn mehrere Threads konkurrierend ohne den Schutz durch synchronized auf die Variable zugreifen können .Zusammenfassung
Wir haben uns in dieser Ausgabe mit den elementaren Grundlagen der Multithread-Programmierung in Java befasst. Dazu haben wir uns detailliert angesehen, wie man potentielle Konflikte beim Zugriff auf ein Objekt aus verschiedenen Threads erkennen kann. Was die Behebung solcher potentiellen Fehler angeht, so haben wir nur diskutiert, was es für eine Methode bedeutet, sie als synchronized zu definieren. In unserem nächsten Artikel werden wir uns die Details von synchronized ansehen sowie die in Java etablierten Idiome zur Benutzung von synchronized .Literaturverweise
| /KRE/ |
Polymorphe Methodenaufrufe und Konstruktoren
Klaus Kreft & Angelika Langer JavaSpektrum, September 2003 URL: http://www.AngelikaLanger.com/Articles/EffectiveJava/07.Clone-Part3/07.Clone-Part3.html |
| /JDOC/ |
Java 2 Platform, Standard Edition, v 1.4.2
API Specification URL: http://java.sun.com/j2se/1.4.2/docs/api/index.html |
| /JLS/ |
Java Language Specification
URL: http://java.sun.com/docs/books/jls/ |
| /PTH/ |
IEEE POSIX 1003.1c
Institute of Electrical and Electronics Engineers, Inc. URL: http://standards.ieee.org URL: http://www.opengroup.org/onlinepubs/007904975/idx/threads.html |
| /JSR166/ |
Specification Request JSR166
Homepage der Arbeitsgruppe zu den Concurrency Utilities URL: http://jcp.org/en/jsr/detail?id=166 |
| /JSR133/ |
Specification Request JSR133
Homepage der Arbeitsgruppe zur Überarbeitung des Java Memory Model URL: http://jcp.org/en/jsr/detail?id=133 |
|
If you are interested to hear more about this and related topics you might want to check out the following seminar: |
||
Seminar
|
||